近年、AIの進歩により音声認識の実用性は劇的に向上し、ビジネスプロセスの一部として組み込むことが一般的となっています。
この記事では、AWSが提供するフルマネージド型音声認識サービス「Transcribe」の機能と使い方、料金体系を詳しく解説します。記事を読むことで、AWSにおける音声認識の理解が深まることでしょう。
「AWS Partner Network (APN) セレクトコンサルティングパートナー」認定の株式会社テクノプロには、AWSに精通した専門エンジニアが多数在籍しております。AWS導入の準備段階からビジネス設計、本稼働、運用の各段階に応じて、経験豊富なエンジニアが効率的に支援を行い、費用対効果の高いサービスを実現します。
テクノプロはAWSの構築から運用まで幅広く支援しています
AWSの音声認識「Amazon Transcribe」とは?機能・仕組み・料金

Transcribeは、AWSが提供するフルマネージド型の自動音声認識サービスです。深層学習 (ディープラーニング) 技術を用いて音声をテキストに変換します。
Amazon Transcribeで実現できること(機能概要)
Transcribeは、音声データを価値ある情報資産へ変換する、AWSの包括的なAIサービスです。長年蓄積された機械学習のノウハウに基づき、MP3やWAVなどの一般的な音声ファイルを高精度なテキストへ自動変換します。サーバーの管理が不要なフルマネージド型サービスであり、トラフィックの増減にも自動で対応しているため、企業の規模を問わず導入できます。
Transcribeの主な機能と特徴は以下の通りです。
| 話者識別 | 複数人の会話でも「誰が」「何を」話したのかを明確に区別して記録 |
|---|---|
| 多言語 | 日本語をはじめとする主要な言語を幅広くカバー |
| カスタム対応 | カスタム語彙機能により社内用語や専門用語の認識精度を向上 |
| 高度なテキスト整形 | 句読点の自動挿入や同音異義語の判別など、読みやすいテキストを生成 |
AWS音声認識の処理方式 : バッチ処理とリアルタイム処理
Transcribeには、業務要件に応じて使い分けることができるバッチ処理と、リアルタイム (ストリーミング) 処理方式があります。
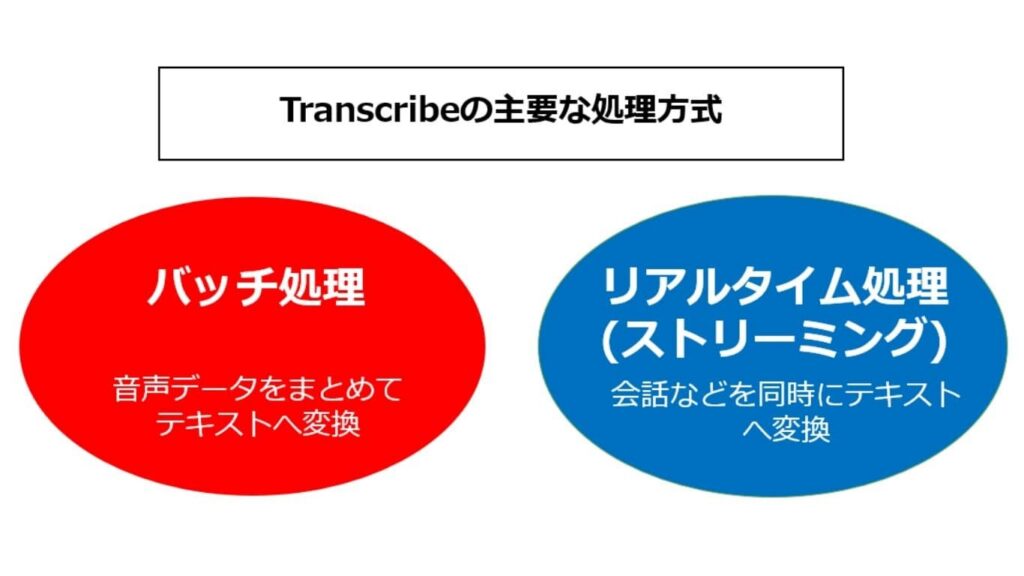
Transcribeのバッチ処理
バッチ処理は、既に録音・保存された音声ファイルをまとめてテキスト化する方式です。非同期処理であり、システム全体の負荷を分散させることで、安定した運用が可能です。
会議の録音データや過去のコールセンターの通話ログなど、即時性を求められない大量のデータを処理することに向いています。ユーザーは、音声データをS3 (AWSのオンラインストレージ) にアップロードしてTranscribeを実行するだけで、テキストデータに変換されます。
Transcribeのリアルタイム処理 (ストリーミング)
リアルタイム処理は、マイクから入力される音声や回線を通じて流れてくる音声を、発話とほぼ同時にテキスト化する方式です。リアルタイム処理の利点は、即時性にあります。
例えば、講演会のリアルタイム字幕生成や、コールセンターにおける会話内容に基づいたFAQの即時提示など、オペレーター支援において低遅延が求められるケースに利用します。発言内容がすぐにテキスト化されるため、会議中の議論をリアルタイムで可視化できるほか、聴覚に障がいのある方へ字幕として情報を提供することも可能です。
リアルタイム処理は、ネットワークの安定性や帯域幅に依存するため、環境によっては遅延や切断が発生するリスクがある点に注意が必要です。
Amazon Transcribeの料金 (コスト)
Transcribeサービスの料金は、「利用した音声の長さ」に応じた従量課金制です。
Transcribeの料金体系を以下に整理しました。
| 音声認識の無料利用枠 | 60分 / 月 (登録から12ヶ月) |
|---|---|
| 音声認識の料金 | $ 0.024 / 分 |
| 音声認識の月100時間利用時料金 (*1) | $ 144 |
*1 料金単価と月間100時間利用時のコスト試算 (スタンダードモデルかつ東京リージョン相当)
例えば、Amazon Transcribeを利用して60分の文字起こしを1日5回、月20日間実施した場合、月間の音声処理時間は約100時間となります。この条件でスタンダードモデルを利用した際の料金は、約$144/月が目安となります。 (2025年11月時点の料金単価をもとに試算)
また、Transcribeは、AWSのサービスと統合して使うことでメリットがあります。AWSのサービスと統合する際のコストは、利用するサービスによって変わるため、PoC (導入前の技術や運用の実現性テスト) による検証が必要です。
実際の業務内容に応じた詳細な料金試算や最適な構成については、AWSパートナーである株式会社テクノプロへお問い合わせください。
Amazon Transcribeと他社サービスを比較|機能・音声認識精度

クラウド型の音声認識市場には、AWS以外にもGoogle CloudやAzureなどの主要ベンダーが参入しています。各サービスにはそれぞれ明確な特徴と強みが存在します。
機能の比較
主要なクラウド音声認識サービスには、Amazon Transcribe・Google Cloud Speech-to-Text・Azure Speech Serviceがあります。基本的な文字起こし能力においては各社高水準である一方、周辺機能やエコシステムとの統合のしやすさには違いが見られます。
次の表は、各サービスの主要機能を比較したものです。
| 比較項目 | Amazon Transcribe | Google Cloud Speech-to-Text | Azure Speech Service |
|---|---|---|---|
| 話者識別 | 対応 (高精度) | 対応 | 対応 |
| カスタム語彙 | 対応 (テーブル形式) | 対応 (リスト形式) | 対応 (リスト形式・テーブル形式) |
| 独自学習モデル | 対応 (テキストデータで学習) | 対応 (テキストデータまたは音声データで学習) | 対応 (テキストデータまたは音声データで学習) |
| 個人情報 (PII) ・マスキング・削除 | 自動対応 (細かい設定ができる) | 自動対応 (DLP APIや外部機能連携も可能) | 自動対応 |
| 業界特化モデル | 医療・コールセンター | 医療・一般電話 | 医療・一般電話 |
| 対応言語数 | 100言語程度 | 125言語程度 | 130言語程度 |
| 音声フォーマット | FLAC・MP3・MP4・Ogg・WebM・AMR・WAV | FLAC・AMR・PCMU・Linear16・OggOpus等 | WAV・MP3・Ogg・FLAC・ALAW・MULAW等 |
Amazon Transcribeは、AWSにおける関連サービス (Connect・Contact Lensなど) との連携が特に強みです。他のAWSサービスと統合することで、通話記録の文字起こし・感情分析・サイレント検出などが自動で行えます。個人情報の編集機能も細かく制御できるため、セキュリティ要件が高い現場での運用にも対応できます (日本語は一部機能制限あり) 。
Google Cloud Speech-to-Textは、グローバルな多言語対応と豊富なデータセットへの対応力が魅力です。医療モデルや電話モデルは共に実用性が高く、DLP APIなどの外部連携による高度なデータ保護・処理も柔軟に利用できます。
Azure Speech Serviceは、130以上の言語に対応し、Microsoft 365やOfficeなど他のMSプロダクトと組み合わせた社内運用の容易さがあります。
各サービスの特徴を理解して、利用用途に応じてサービスを選定することが大切です。
音声認識精度の比較
音声認識の精度は、単語誤り率という指標で評価します。録音環境や専門用語の有無によって結果が変わるため、どのサービスが常に優れていると一概には言えませんが、各社の学習データの背景により、得意とする領域に明確な違いがあります。
音声認識精度を以下に整理します。
| サービス名 | 精度の特徴・強み | 活用シーン |
|---|---|---|
| Amazon Transcribe | ・文脈を理解した自然な句読点の挿入や、複数話者の聞き分けが高精度 ・8 kHz (電話) と16 kHz (広帯域) のモデル選択が可能 | ・会議の議事録作成 ・コールセンター分析 ・複数人が話すインタビュー |
| Google Cloud Speech-to-Text | ・Google検索の膨大なデータを背景に持つ ・新しいトレンド用語や固有名詞・地名などの認識に強みがある | ・Web動画の字幕生成 ・一般消費者向けの会話 ・最新用語が多いコンテンツ |
| Azure Speech Service | ・人間のような自然な会話の認識に定評あり ・Teamsなどの技術基盤を活かしたビジネス会話全般に強い | ・ビジネス全般 ・Office製品との連携 ・対話型ボットの入力 |
Amazon Transcribeは、高精度な話者識別が必要な場合に優位性があります。最新の用語を含む音声ならGoogle Cloud Speech-to-Text、ビジネス用途はAzure Speech Serviceに強みがあります。
比較結果から見るAmazon Transcribeの「強み」と「弱み」
Transcribeの強みと弱みは以下の通りです。
| 強み | ・S3連携による自動化フローが容易で、開発・運用コストを大幅に削減できる ・カスタム語彙機能により、業界用語や社内用語の認識精度を向上させることができる ・データがAWS環境内で完結するため、高いセキュリティとコンプライアンスを確保できる |
|---|---|
| 弱み | ・方言や独特な口語表現では誤変換が生じる場合がある ・文脈から意味を推測・補完する能力で劣る場合がある |
Transcribeは、運用の安全性と効率性において優位性があり、セキュリティを重視する企業にとっては、高精度な文字起こしと安全なデータ管理を両立できるため、信頼性の高い選択肢といえます。
一方で、砕けた会話のニュアンスを理解する点には課題が残りますが、継続的なアップデートにより日々改善されています。
Amazon Transcribeの使い方

Transcribeを利用開始するためのプロセスは非常にシンプルです。
AWSマネジメントコンソール (AWSの各サービスを操作・管理するツール) を使用すれば、プログラミングの知識がなくても直感的な操作で音声認識を実行できます。
AWSアカウントの作成
AWSの公式サイトにアクセスします。画面の右上にある言語から日本語を選択してからアカウント作成を開始してください。
アカウントの作成は画面の指示に従って以下の情報を入力すれば作成できます。
| ・メールアドレス ・パスワード ・氏名 ・連絡先 (住所や電話番号など) ・会社名 (必要に応じて) ・クレジットカード情報・SMS認証用の電話番号 |
S3の準備

以下の手順で進めます。
| 1.AWSマネジメントコンソールにアクセス 2.AWSマネジメントコンソールで「S3」を選択し、音声データ保管用の新しいバケットを作成 3.任意のバケット名とリージョンを指定 |
必要に応じてアクセス権限やバージョニング、暗号化オプションを設定すれば完了です。
音声データのアップロード

以下の手順で音声データをアップロードします。
| 1.AWSマネジメントコンソールで作成したS3を開く 2.「アップロード」ボタンから音声データを選択してアップロード |
ドラッグ&ドロップやファイル選択で複数ファイルも一度に指定することが可能です。アップロード後は、バケット内の「オブジェクト」一覧から音声データの保存を確認できます。
文字起こしジョブの作成
AWSコンソールで「Transcribe」を選択し、文字起こし処理を画面の指示に従いジョブを作成します。
ジョブは以下の流れで作成します。
| 1.サービス一覧から「Transcribe」を選択し、左側のメニューから「Transcription jobs」をクリック 2.「Create job」ボタンを押し、ジョブ設定画面で「Name (ジョブ名) 」を入力し言語を選択 3.「Input data (入力データ) 」の項目で「Browse S3」をクリックし、音声ファイルを指定 |
オプション設定として、話者識別機能の有効化・カスタム語彙の適用・フォーマットの指定などを行うことができます。
特にビジネス会議の議事録を作成する際は、話者識別をオンにし、予想される話者数を入力しておくことで、誰の発言かを区別したアウトプットを得ることが可能です。
さらに、PII (個人情報) の削除オプションを有効にすることで、セキュリティを強化することもできます。
音声認識の実行と確認
ジョブ作成後、AWSマネジメントコンソールを使いTranscribeが自動的に音声認識処理を実行します。処理が完了すると、「Transcription jobs」画面でジョブのステータスが「Completed」になります。
結果は、ジョブ名をクリックすれば確認可能です。
ジョブ名をクリックすると、文字起こし結果 (トランスクリプト) ・タイムスタンプ・話者ラベル・信頼度スコアなどが確認できます。結果はJSON形式でダウンロードすることもできます。
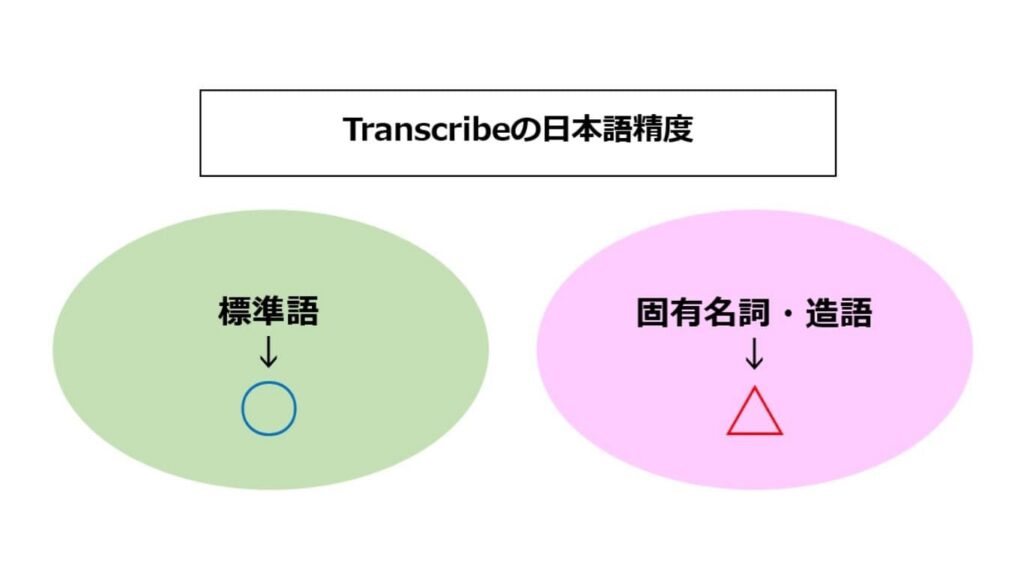
Amazon Transcribeにおける日本語の音声認識精度

Transcribeの日本語認識能力は、継続的なモデル改善によって、実務で十分に活用できるレベルに達しています。
ここでは、日本語における音声認識の精度を解説します。
日本語精度に関する実務上の評価
Transcribeの日本語モデルを実務的な観点から評価すると、標準語で明瞭に話された音声に対しては高い認識精度があります。特にニュース音声やプレゼンテーションのように、1人が明確な口調で話すコンテンツでは高品質なテキストを出力可能で、修正の手間はほとんどかかりません。
| 助詞(て/に/を/は)や敬語表現 | 文脈を考慮して自然な形に変換される傾向 |
|---|---|
| 句読点の自動挿入機能 | 句点(。) ・読点 (、) ・疑問符 (?) が適切な位置に付与される |
しかし、一般的でない固有名詞や新しい造語や略語に関しては、音としては正しくても漢字変換が誤っていることや、全く別の言葉に置き換えられることがあります。
これらはカスタム語彙機能で事前登録することで精度を向上できます。
一般的なビジネス会話の議事録作成支援や、動画の字幕生成のベースとしては非常に有用と言えますが、契約書作成のように一言一句の正確性が法的に求められる業務においては、人の目によるダブルチェックが必要です。
音声認識の精度が課題となるケース
Transcribeは、録音環境や話者の話し方により精度が低下するケースが存在します。
具体的に精度が低下するケースは以下の通りです。
| 雑音 (ノイズ) が多い環境 | ・例:空調の音・屋外の交通騒音・BGMなどが音声に混入しているケース ・AIが人間の声を正確に分離できず誤認識の原因となる |
|---|---|
| マイクが遠い/音質が悪い | ・例:ICレコーダーを机の中央に置いて多人数で会議をするケース ・マイクから遠い席の人の声が反響する場合や、音量が小さすぎる場合は、音声を正しく認識できない |
| 話者同士の発言が重なる | ・例:激しい議論などで複数人が同時に喋るケース ・音声波形が重なり合い、AIはどの言葉を拾えばよいか判断できない |
精度が低下するケースの対処には以下があります。
| ・ピンマイクを使用して個別に集音する ・発言のタイミングが被らないようにルールを決める ・ノイズキャンセリング機能を持つマイクを使用する |
音声の精度低下を抑えるには、音声データを収集する段階で注意する必要があります。
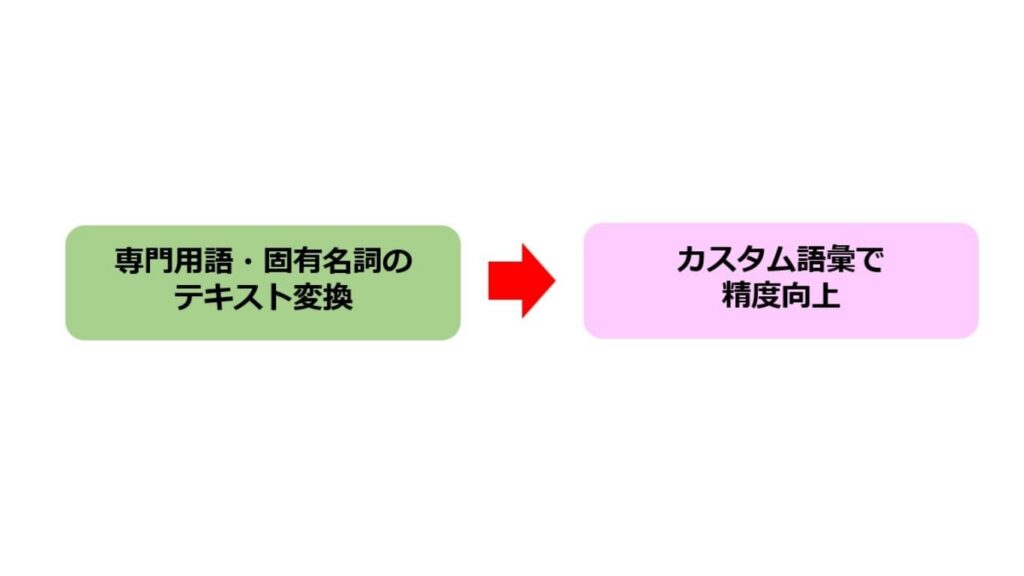
カスタム語彙を用いた精度向上
カスタム語彙は、一般的なモデルでは認識が難しい専門用語や固有名詞の認識精度を向上させる機能です。
製品名・プロジェクトコード・業界用語などをあらかじめテーブルとして登録します。ジョブ実行時にカスタム語彙を指定することで、AIが対象の単語を優先的に認識するようになります。
カスタム語彙では、DisplayAs機能を使って表記揺れを制御することが可能です。例えば、音声では「エーダブリューエス」と発音されても、テキスト出力では「AWS」と統一表記させることができます。
カスタム語彙の登録にはテーブル形式の利用が推奨されており、リスト形式は非推奨です。誤認識された単語をテーブルに追加して再実行するというチューニングのサイクルを回すことで、自社の業務に特化した高精度なモデルへと最適化できます。
また、機密データ・個人情報 (PII) ・保護対象医療情報 (PHI) をカスタム語彙に登録することは危険です。カスタム語彙はAWS側に保存されるため、セキュリティリスクにつながります。
カスタム語彙を利用する際の注意点
カスタム語彙は強力な機能ですが、登録可能な語彙数やファイルサイズなどの技術的な制約があるため、不要な単語を多数登録すると管理が煩雑になります。
▼カスタム語彙の制約例
| ・カスタム語彙はサイズの上限 (50 KB) がある ・ファイルはUTF-8形式で作成 ・特殊文字や記号の使用にも細かいルールが存在 ・各エントリーは256 文字未満 |
ポイントは、本当に必要な単語に絞って登録することです。
登録や更新はコンソールやAPIから行えます。長期的な品質維持のためには、定期的なカスタム語彙メンテナンスを運用に組み込むことが大切です。
Amazon Transcribeのリアルタイム音声認識

Transcribeのリアルタイム処理は、発話とほぼ同時にテキストを出力します。Transcribeを使うことで、即時性が求められるアプリケーションの構築を実現します。
遅延に関する実務上の評価
Transcribeのリアルタイム処理は、ライブ字幕やオペレーター支援などの業務に対応できる実用的なスピードを備えています。
発話終了からテキストが完全に確定するまでには数秒程度のラグが生じますが、以下の仕組みにより、ユーザーはストレスなく利用できます。
| ・認識できた単語から順次、画面に表示される ・文脈が確定した時点で、正しいテキストに自動修正される |
これにより「体感的な遅延」は最小限に抑えられています。しかしながら、同時通訳のようにコンマ数秒を争うケースでは、ネットワーク環境も含めた慎重な設計が必要です。
リアルタイム処理のポイント
リアルタイム音声認識の実装には、主にHTTP/2またはWebSocketという通信プロトコルが使用されます。どちらも音声ストリームを継続的に送信する点は共通していますが、接続元により遅延 (レイテンシー) に差が生まれます。
WebSocketを用いてブラウザやアプリからTranscribeへ直接接続する方法は、遅延を抑えるための有効な構成です。ブラウザやアプリとTranscribeの間にサーバーを挟まないため、音声データは最短経路でAWSに届き、結果も即座に返ってきます。
また、AWSが提供する主要言語向けSDK (JavaScript・Python・Javaなど) を利用すれば、複雑な処理を意識せずに実装が可能です。
一方で、HTTP/2は主にサーバーサイドでの処理に向いています。クライアントから自社サーバーを経由してAWSに送信するため、セキュリティを制御しやすい構成です。しかしながら、ネットワークの経路が増えるため、遅延がわずかに増加する課題もあります。
これらを考慮して、本格導入前のPoCでは、以下の観点で実運用に耐えうるか検証する必要があります。
| ・実際のネットワーク環境で業務への遅延影響を検証 ・使用するマイクごとの精度や周囲の雑音による影響を確認 ・ネットワーク切断時の再接続処理や復帰の挙動を検証 |
開発時は、PoCの結果を考慮して実際の環境に合わせたチューニングが必要です。
Amazon Transcribeのセキュリティ

企業がクラウドを利用する際の懸念点としてデータのセキュリティがあります。Transcribeは、AWSの強固なセキュリティ基準に準拠しており、機密性の高い音声データでも安心して利用できます。
以下で詳しく解説します。
PIIマスキングによるセキュリティ対策
Transcribeには、英語モデルなどで利用可能なPII (個人特定情報) の自動マスキング機能が存在します。しかし、現時点では日本語はサポート対象外です。また、対応言語であっても、バッチ処理とリアルタイム処理で対応するPIIのタイプが異なります。
日本語の音声データを文字起こしする場合、マイナンバー・氏名・電話番号などの機密情報は伏せ字にされず、そのままテキストとして出力されます。「自動で隠してくれる」という前提で運用すると、重大なインシデントにつながるため注意が必要です。
また、PIIの自動マスキング機能は万能ではありません。AWS公式ドキュメントには、機械学習は予測に基づくため、すべての機密データを完全に除去できる保証はないと明記されています。このため、出力結果を人の目で確認することが強く推奨されています。
さらに、本機能はHIPAAなどの医療プライバシー法に基づく匿名化要件を満たしません。したがって、医療分野など、匿名化が求められる用途には不適切です。
以下の代替策や厳重なデータ管理が必要です。
| 暗号化による保護 | S3 (AWSのオンラインストレージ) の暗号化やKMS (データ暗号化に用いる鍵を管理するAWSサービス) を利用してデータそのものを強力に保護する |
|---|---|
| アクセス権限の最小化 | IAM (AWSリソースへのアクセスセキュリティ管理) ポリシーを活用してデータへのアクセス権限を最小限に絞る |
| 独自の後処理 | Lambda等による独自の置換処理の実装や目視チェック工程を検討する |
日本語環境では、機能の制約を正しく理解し、ツール任せにせずにセキュリティ対策を行うことが大切です。
その他のセキュリティ対策
Transcribeは、AWSの堅牢なインフラストラクチャ上で動作しており、企業のコンプライアンス要件を満たすための多様なセキュリティ機能を提供しています。
特に重要な4つの対策は以下の通りです。
| ・暗号化して安全にデータを保存 ・VPCエンドポイントによる閉域網接続 ・ログ監視 ・厳密なアクセス制御 |
これらの機能を組み合わせることで、金融機関や医療機関など、高いセキュリティレベルが求められる業界でも安心して利用できます。
以下で解説します。
暗号化して安全にデータを保存
保存データ (S3) と転送データ (TLS) の両方で強力な暗号化が適用されます。また、データはユーザーが指定したリージョンから外に出ることはないため、データの保存場所に関する規制もクリアできます。
VPCエンドポイントによる閉域網接続
インターネットを経由せず、AWS内のVPC (仮想プライベートクラウド) から直接Transcribeに接続することが可能です。これにより、社内システムからの通信を外部にさらすことなく、安全な経路を確保できます。
ログ監視
いつ・誰が・どのファイルに対して文字起こしを実行したかという操作ログは、すべてAWS CloudTrailに記録されます。これにより、不正アクセスの追跡や監査対応が容易です。
厳密なアクセス制御
IAMにより、「特定のIPアドレスからのみアクセスを許可する」「特定のバケットのみ読み取りを許可する」といった詳細なポリシーを設定できます。
AWS音声認識の導入前に確認すべきポイント

Transcribeの料金は、初期費用なしの従量課金制です。使った分だけ支払う透明性の高いモデルとなります。しかし、リージョンや機能によって単価が異なるため注意が必要です。
導入判断のための評価軸
Transcribeの導入を検討する際は、単なる機能の有無だけでなく、実運用を見据えた多角的な評価が必要です。
主要な4つの評価項目を、検討内容と優先度の観点で整理しました。
| 項目名 | 検討内容 | 優先度 |
|---|---|---|
| 音声認識精度 | ・自社の専門用語や製品名は「カスタム語彙」で認識可能か ・日本語特有の言い回しや雑音環境下での精度は許容範囲か ・PoCで実データを用いたテストを行ったか | 高 |
| コスト | ・従量課金 (分単価) だけでなく、S3保管料などを含めたTCOは適正か ・無料利用枠 (最初の12ヶ月・月60分) を活用できるか ・15秒未満のリクエストは15秒分として課金される最小課金単位の仕様を理解しているか | 高 |
| セキュリティ | ・日本語で自動マスキングが使えない前提で、暗号化やVPC接続による代替策は十分か ・アクセス権限やログ監視の要件を満たせるか | 最高 |
| AWS連携性 | ・S3へのファイルアップロードをトリガーとした自動化フローが組めるか ・Lambdaなど他のAWSサービスと連携し、開発工数を削減できるか | 中 |
特にセキュリティは、日本語環境における自動マスキング機能が非対応のため、暗号化や閉域網接続といったインフラ側での対策が必要です。表の基準に照らし合わせ、自社の要件と合致するかを判断してください。
導入時の課題と解決策
Transcribeの導入においては、いくつかの典型的な課題に直面することがあります。
主要な4つの課題について、原因と具体的な解決策を整理しました。
| 項目名 | 検討内容 | 優先度 |
|---|---|---|
| 日本語認識の精度 | 同音異義語・専門用語・方言などが多く、汎用モデルだけでは正確に変換できない場合がある | ・カスタム語彙を活用し、社内用語や製品名を登録してチューニングを行う ・マイクの位置や録音環境を見直し、入力音声の質を高める |
| リアルタイム処理での遅延 | ネットワーク環境や通信プロトコルのオーバーヘッドにより、数秒程度のタイムラグが発生する | ・WebSocketを利用した直接接続を採用し、通信経路を最適化する ・「完全にゼロ遅延ではない」という前提で、ユーザー体験 (UX) を設計する |
| コストの見積もり難 | 総額が見えにくく、予算取りが難しい | ・Pricing Calculatorを用いて、想定利用量に基づいた試算を行う ・PoCを実施し、実データでの課金実績を元に本番予算を策定する |
| 専門知識不足 | AWSのインフラ (S3・IAM・SDKなど) に関する知識がなく、実装や運用に不安がある | ・フルマネージド型サービスであるTranscribeの利点を活かし、サーバー管理の手間を省く ・AWS公式のハンズオンや、認定パートナーの支援を活用する |
これらの課題は、事前に原因を特定し、適切なAWS機能やツールを組み合わせることで解消できます。特に「精度」と「コスト」は、PoCを行い事前に検証することで解決できます。
検証時の注意点(PoCの確認ポイント)
本格導入後のミスマッチを防ぐためには、実際の利用環境に近い条件下でのPoCの実施が大切です。
PoCで重点的に確認すべき4つの項目を整理しました。
| 項目名 | 目的 | 確認方法 |
|---|---|---|
| 音質・マイク環境 | AIが認識しやすい最適な入力デバイスと録音設定を特定し、精度のベースラインを確保する | ・指向性マイク、ヘッドセット、PC内蔵マイクなど複数のデバイスで比較する ・サンプリングレート (16 kHz推奨) が適切か確認する |
| ノイズ対策 | 実業務の環境 (オフィスの話し声や空調音など) が認識精度に与える影響度を測定する | ・静かな会議室と、雑音のある執務スペースで同じ会話を録音して比較する ・必要に応じてノイズキャンセリングツールの併用を検討する |
| カスタム語彙の有効性 | 社内用語や製品名が正しく変換されるかを確認し、チューニングによる改善幅を把握する | ・専門用語を含む会話データを「カスタム語彙なし」と「あり」の両方で処理する ・誤認識された単語をテーブルに追加し、どれだけ精度が向上するか検証する |
| 課金体系・無料枠条件 | 想定外のコスト発生を防ぐため、実際の処理時間と請求額の整合性を確認する | ・AWS Billing (請求ダッシュボード) を確認し、バッチ処理およびストリーミング処理における「実際の音声処理時間」での課金仕様と実際の請求額を突合する ・15秒未満のリクエストは15秒分として課金される最小課金単位の仕様を確認する ・無料利用枠 (最初の12ヶ月・月60分) が適用されているか確認する |
PoCを通じて、自社の環境における精度の課題と必要コストを把握することが、導入成功のポイントです。
まとめ
本記事では、AWSの音声認識サービス「Transcribe」について、機能・比較優位性・利用方法・実務上の評価までを網羅的に解説しました。
Transcribeは、S3へ音声ファイルをアップロードすることで、すぐに試すことができます。まずは無料利用枠を活用して、自社のデータで音声認識の精度と利便性を体験してはいかがでしょうか。クラウドサーバーの構築支援なら、国内25,000人以上(※1)の技術者を擁し、大手企業を中心に2,555社との取引実績(※2)を持つ株式会社テクノプロにお任せください。最適な運用設計から監視・障害対応・コスト最適化まで、一括して任せることができます。
※1:2024年6月末時点
※2:(株)テクノプロ及び(株)テクノプロ・コンストラクション 2024年6月末時点
監修者

テクノプロ・ホールディングス株式会社
チーフマネージャー
中島 健治
2001年入社
ITエンジニアとして25年のキャリアを持ち、チーフマネージャーとしてテクノプロ・エンジニアリング社にて金融・商社・製造業など多業界でのインフラ基盤構築に従事してきた。2008年から2024年まで、オンプレミス環境でのストレージ・サーバ統合基盤の設計・構築を手掛け、特に生成AI・データ利活用分野のソリューション開発実績が評価されている。現在は技術知見を活かしたマーケティング戦略を推進している。






