現代のビジネス環境において、企業が取り扱う画像データの取り扱い量は膨大であり、目視で確認することは、時間やコストの面から現実的ではありません。そこで必要不可欠となる技術が画像認識技術です。
本記事では、AWSが提供するフルマネージド型の画像・動画分析サービス「Amazon Rekognition」の機能から料金体系や事例まで網羅的に解説します。本記事を読むことで、AWSでAmazon Rekognitionを導入する具体的なイメージがつかめることでしょう。
「AWS Partner Network (APN) セレクトコンサルティングパートナー」認定の株式会社テクノプロには、AWSに精通した専門エンジニアが多数在籍しております。AWS導入の準備段階からビジネス設計、本稼働、運用の各段階に応じて、経験豊富なエンジニアが効率的に支援を行い、費用対効果の高いサービスを実現します。
テクノプロはAWSの構築から運用まで幅広く支援しています
AWSの画像認識サービス「Amazon Rekognition」とは

Amazon RekognitionはAWS画像認識の核となるサービスです。ここではAmazon Rekognitionの概要を説明します。
Amazon Rekognitionとは?概要と主な特徴
Amazon Rekognitionは、画像および動画分析に特化したフルマネージド型AIサービスです。ユーザーはインフラの構築や管理、複雑なアルゴリズムの選定を行う必要はありません。分析したいデータを渡すだけで、分析結果 (ラベル・信頼度スコアなど) を受け取ることができます。
また、Amazon Rekognitionは分析結果と信頼度を提供するサービスです。最終的な判断 (本人確認の可否など) は業務要件に応じた実装を行います。重要な用途では必要に応じて人手による確認を組み合わせることが前提です。
具体的には、次のようなタスクを人間よりも遥かに高速かつ正確に実行します。
| ・ラベル検出: 画像の中に何が写っているか確認する ・顔認識: 誰が写っているか確認する ・モデレーション: 不適切な内容が含まれていないか確認する |
Amazon Rekognitionの主な特徴は次の4つです。
| 専門知識が不要 | ・機械学習 (ML) などの専門家がいなくても利用できる ・シンプルなAPI呼び出しのみで高度な画像分析ができる ・AIモデルの開発やトレーニングというハードルなく導入できる |
|---|---|
| 高精度な学習済みモデル | ・AWSが事前学習した汎用モデルを即座に利用できる ・一般的な物体、シーン、顔、テキストなどは、追加学習なしで高い精度で認識される |
| スケーラビリティ | ・サーバーの増強計画を立てる必要がない ・ビジネスの規模に合わせて自動的にリソースが拡張される |
| 低コスト | ・初期費用が不要 ・分析した画像枚数や動画の分数に応じた従量課金制 |
AWSのAIサービス群におけるAmazon Rekognitionの位置づけ
AWSが提供する機械学習スタックは、ユーザーのスキルレベルやニーズに応じて最上位層・中間層・最下層の3レイヤーに分類されます。
レイヤーを理解することで、なぜAmazon Rekognitionを選択すべきかが明確になります。
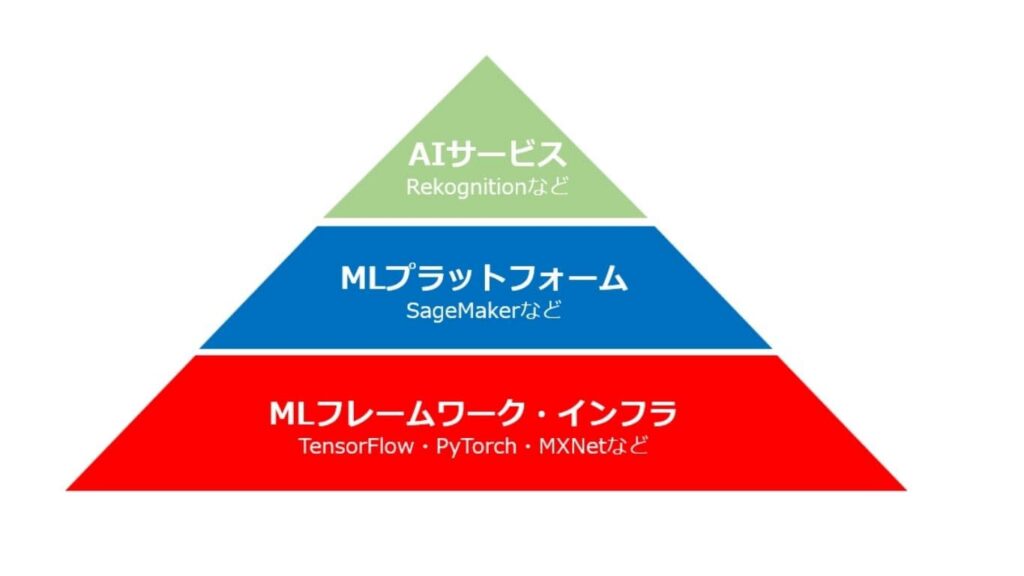
| 最上位層 | ・誰でも高度なAI機能の利用を可能にするサービス群 ・複雑なモデル構築はAWSに任せ、ユーザーは必要な機能を呼び出すだけで済む ・Amazon Rekognitionはこの層の中で、人間の目に当たる視覚 (画像・動画) 分析を一手に担う |
|---|---|
| 中間層 | ・MLプラットフォーム ・既存のサービスでは満たせないニーズに応えるオーダーメイド開発のための環境 ・SageMakerが代表的 |
| 最下層 | ・MLフレームワーク (機械学習モデルを構築・トレーニング・デプロイする機能の集合体) とインフラ ・TensorFlowやPyTorch、MXNetなどのフレームワークをEC2上で直接動作 ・研究者や、最先端の独自モデルをゼロから開発する高度な専門家向け |
AWSにおけるAIサービスの中で、Amazon Rekognitionは手軽さとスピードを最優先し、かつ品質の高精度なモデルを利用したいユーザーにとって合理的な選択肢となります。特に「画像認識機能をアプリに追加したくても社内にAIエンジニアがいない」というケースでは、Amazon Rekognition一択といえます。
Amazon Rekognitionの主要機能

Amazon Rekognitionは単一の機能ではなく、多岐にわたる分析機能の集合体です。ここでは、ビジネスで頻繁に利用される主要な8つの機能について深掘りして解説します。
顔の検出・分析・認証
Amazon Rekognitionの代名詞ともいえるのが顔認識機能です。顔認識機能は、顔があることを検知するだけでなく、顔の分析、顔の認証に分かれます。
| 顔の検出 | ・画像内のどこに顔があるかを示す位置情報を返す機能 ・目・鼻・口などの主要なパーツの位置も特定→顔の向きや傾きを正確に把握 |
|---|---|
| 顔の分析 | ・検出された顔の属性を推定 ・年齢層・性別・感情・目が開いているか、眼鏡やサングラスを着用しているかなどを判定 ・画像の品質 (明るさや鮮明度など) や顔のポーズも数値化 |
| 顔認証 | ・事前に作成した顔画像のデータベースに対し、入力された画像を照合 ・1対1の比較 (本人確認) や、1対Nの特定人物の特定 ・各顔データはベクトル化 (数値化) されて保存されるため、高速な検索が可能 |
なりすまし防止 (Face Liveness)
Face Livenessは、「なりすまし」のリスクを低減する機能です。
ユーザーに対してカメラの前で指定されたアクションを行うよう促し、照明の反射や微細な肌の質感を解析することで、対象が実在する生身の人間である可能性を判定します。
ただし、判定結果は0〜100の信頼度スコアとして返却され、確率的な評価に基づくため、なりすまし防止を100%保証するものではありません。
また、重要な本人確認が必要な業務では、Face Livenessの判定結果のみに依存せず、多要素認証 (パスワード・SMSコード等) や本人確認書類との照合、必要に応じた人手による確認など、複数の認証手段を組み合わせることが前提です。
Face Livenessは、従量課金制で提供され、特別なハードウェアを必要としない点もメリットです。
ラベル検出・物体検出
ラベル検出・物体検出は、画像の中に何が写っているかをAIが理解するための機能です。
Amazon Rekognitionでは、画像に写っている数千種類以上の物体 (犬や車など) ・シーン (ビーチやオフィスなど) ・概念 (自然やテクノロジーなど) を特定し、識別しやすいキーワードをラベルとして出力結果に付与します。
以下の表は、ラベル検出・物体検出の主な特徴と活用ポイントをまとめました。
| ラベルの階層構造 | ・例えば「自動車」が検出されると、同時に上位概念の「乗り物」なども付与され、どちらのラベルでも検索・分類が可能 |
|---|---|
| 信頼度スコア の付与 | ・各ラベルにはAIが判断の確度を示すスコア(0〜100%)が付与される ・「信頼度90%以上のみ採用」といったフィルタリングが可能 |
| 位置情報の提供 | ・画像内の特定箇所に対象がどこに存在するか座標情報を付与 ・物体の切り出し、人物検知、セキュリティ領域監視などに活用 |
カスタムラベル (独自モデルの学習)
標準のラベル検出は汎用的ですが、業務では「自社製品」「特定のパーツ」「ブランドロゴ」など、独自の対象を識別したいケースがあります。
Amazon Rekognition Custom Labelsでは、巨大な学習済みモデルをベースにユーザーのデータに合わせて微調整を行う技術によって、圧倒的に少ないデータ量 (数十枚〜数百枚程度) と短い時間で、高精度なモデル構築が可能です。
ユーザーは画像にラベル付けをするだけで、モデル学習やチューニングは自動化されているため、機械学習の専門知識がなくても利用できます。
「汎用モデルでは判別できない対象を識別したい」というシーンで特に有効です。
テキスト検出 (画像内の文字認識)
テキスト検出は、画像や動画に含まれるテキスト情報を検出し、文字列として抽出する機能です。
多言語に対応しており、英語だけでなく、日本語を含む多様な言語に対応しつつあります。文字の傾きや歪みにも強く、各単語や行ごとの位置情報の返却も可能です。
テキスト検出は、例えば次のように活用されています。
| ・街中の看板や道路標識の読み取り ・テレビ映像やYouTube動画内のテロップの抽出 ・車両のナンバープレートの認識 ・商品パッケージの成分表示の読み取り |
Amazon Rekognitionのテキスト検出は、一般的なドキュメントスキャナとは異なり、自然風景の中にある文字の認識に強みがあります。
一方で、紙の書類や帳票のデータ化に関しては、Amazon Rekognitionのテキスト検出ではなく、Textractの使用が推奨されます。
Amazon RekognitionとTextractの得意領域を整理すると次の通りです。
| サービス | 得意な領域 | 主な用途 |
|---|---|---|
| Amazon Rekognition | 顔の分析・自然風景・看板・物体上の文字・変形した文字 | 顔認証・ナンバープレート認識・看板の文字抽出・テロップ解析 |
| Textract | 文書・帳票・スキャンデータ・PDF | 請求書処理・本人確認書類 (免許証等) のOCR・手書き文字認識 |
Textractはスキャナーのような用途に使い、それ以外はAmazon Rekognitionというのが一つの判断基準となります。
安全でないコンテンツの検出 (モデレーション)
モデレーション機能は、画像に含まれる不適切または不快なコンテンツを自動的に検出する機能です。
SNSにおいて、ユーザーが投稿する画像や動画を監視し、健全性を保つことは重要である一方、人手で膨大な情報をすべてチェックすることは不可能です。
Amazon Rekognitionを活用することで、実運用に即した効率的な監視システムを構築できます。具体的には、以下のようなリスクのある要素を広範囲かつ詳細に分類して検出することが可能です。
| ・露骨な露出 ・暴力 ・ドラッグ ・ヘイトシンボル |
これらの判定結果には階層構造が取り入れられています。
例えば、露骨な露出という大枠の下に「水着」や「グラビア」といった細かい分類が定義されているとします。Amazon Rekognitionは「水着は許可、完全な露出は禁止」といった、サイトのポリシーに合わせたフィルタリングが可能です。
また、完全な自動化だけでなく、A2I (Augmented AI) との連携もできます。
例えば、AI判定において信頼度の低い微妙な画像は、人間の担当者に回すといったワークフローを作れば、自動化による効率性と人の目による精度のバランスを取った対応もできます。
個人用保護具 (PPE) の検出
個人用保護具 (PPE) の検出は、労働安全衛生 (HSE) の遵守が求められる建設・製造・化学プラントなどの現場において、「頭部にヘルメットがあるか」「顔にマスクがあるか」といった部位ごとの画像判定を個別に行うことができます。
単に未着用を検知するだけでなく誰が着用していないかを特定できる点も特徴です。
問題を検知できれば、管理者や該当作業員へアラートを送るといった具体的なアクションに繋げることができます。
個人用保護具の検出により、監督者が常時監視していなくても違反リスクを低減できます。
Amazon Rekognitionの料金体系

Amazon Rekognitionの料金モデルは、クラウドサービス特有の従量課金制です。初期費用や最低利用料はなく、実際に処理したデータ量に基づいて計算されます。
機能によって課金単位が異なるため、事前の試算が重要です。
無料利用枠と従量課金 (APIコール課金)
AWSアカウント作成後には、一定期間利用できる無料利用枠が用意されています。無料枠を活用することで、サービスの学習や初期のPoC (概念実証) を十分に実施することができます。
無料利用枠の対象となる主な項目は次の通りです。
| ・期間: アカウント作成から一定期間 ・画像分析 (ラベル検出、顔認識など): 毎月一定枚数まで無料 ・顔メタデータストレージ: 一定数の顔ベクトル保存まで無料 ・Custom Labels: 毎月一定時間のトレーニングと推論まで無料 ・Video分析: 毎月一定分数まで無料 |
無料枠を超えるか無料の期間が終了した場合は、従量課金が適用されます。
従量課金の基本ルールは次の通りです。
| 画像分析 (ラベル・顔認識・モデレーション・テキスト検出など) | ・処理した画像の枚数に応じて課金 ・月間の処理枚数が増えるほど単価が段階的に下がるボリュームディスカウントが適用される |
|---|---|
| 顔メタデータのストレージ | ・保存した顔メタデータの数と期間に応じて課金 |
| 動画分析 (Video API) | ・処理した動画の分数に応じて課金 ・ライブストリーミング動画と保存された動画で料金体系が異なる |
| Custom Labels | ・トレーニング時間 (モデルの学習時間) と推論時間 (モデルが起動している時間) に応じて課金 ・推論時間は、APIを呼び出していなくてもモデルが起動している状態であれば課金され続けるため注意 |
| Face Liveness | ・チェック実行回数に応じて課金 ・無料枠がない点に注意 |
具体的な無料利用枠の詳細や料金単価は、利用用途やリージョンによって変わります。また、Face Livenessは無料枠がありません。無料枠や料金体系は不定期で改定されるため、Amazon Rekognitionの利用前にAWS公式サイト「Amazon Rekognitionの料金」で最新情報をご確認ください。
また、 同じ画像に対して複数のAPIを実行すると、それぞれのAPIごとに課金されるため注意が必要です。
API以外にかかる費用 (S3など) の落とし穴
Amazon Rekognitionを利用する際は、API料金だけでなく、システム全体でのトータルコストを意識する必要があります。特に以下の要素は見落とされがちなため、注意が必要です。
| S3の料金 | 分析対象の画像や動画を保存しておくための料金 * 長期間大量のデータを保存する場合、S3ライフサイクルポリシー (古いデータを安いストレージクラスに移動する設定) の活用を推奨 |
|---|---|
| データ転送量 | 分析結果や画像をAWSから外部にダウンロードする場合の転送料金 |
| Kinesis Video Streams | 動画のライブストリーミング分析で動画データを取り込むために必要な料金 * 動画の容量と保持期間に比例するため、高解像度の動画を扱う場合はコストが膨らむ可能性があり |
コストを最適化するためには、必要な画像だけを分析する (フィルタリング) 、解像度を必要十分なレベルに下げる、Custom Labelsモデルのこまめな停止といった運用上の工夫が必要です。
Amazon Rekognitionの使い方|Python実装例・構成イメージ付き

ここでは、Amazon Rekognitionをシステムに組み込むための具体的な手順を説明します。Pythonを用いたサンプルコードや本番環境を想定したアーキテクチャ構成も合わせて紹介します。理解を深めてください。
Amazon Rekognitionを利用した基本アーキテクチャと本番構成例
Amazon Rekognitionは単体で使うよりも、他のAWSサービスと組み合わせることで真価を発揮します。
ここでは代表的なイベント駆動型サーバーレスアーキテクチャを紹介します。
Amazon Rekognitionを利用した基本アーキテクチャ (S3 → Lambda → Amazon Rekognition)
基本的なアーキテクチャのイメージと処理の流れは次の通りです。
| イメージ | 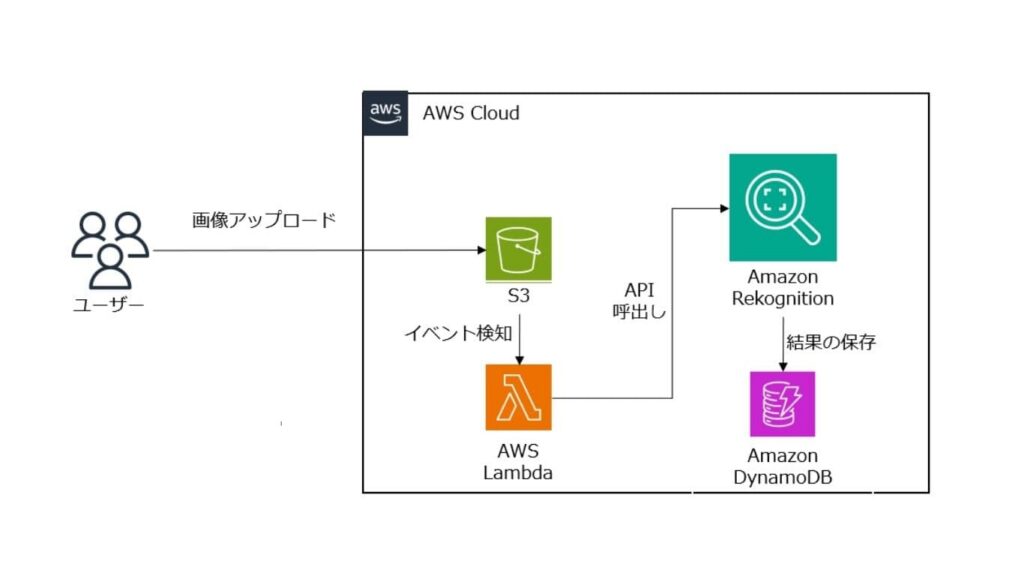 |
|---|---|
| 画像アップロード | ユーザーがスマホアプリから画像をS3にアップロード |
| イベント検知 | S3がファイルの作成を検知し、自動的にLambda (サーバーレスコンピューティング) の関数を起動 |
| API呼出し | Lambda上のプログラムが起動してAmazon RekognitionのAPI呼出し |
| 結果の保存 | Amazon Rekognitionから返却されたJSON形式の分析結果をDynamoDB (NoSQLデータベース) にメタデータとして保存 * 結果はアプリケーションからいつでも検索可能な状態となる |
この構成では、サーバー (EC2) を常時起動する必要はありません。画像がアップロードされた瞬間だけ処理が走るため、コスト効率と管理の容易さに優れています。
本番運用の構成例
本番環境では基本アーキテクチャをベースに、安全性と信頼性を高めるための設計が必要です。
一般的には、次のような構成を追加します。
| API Gateway | 外部からのリクエストを安全に受け付け、流量制限などでシステムを保護する |
|---|---|
| SQS | リクエストを一時的に蓄積し、大量アクセス時でも処理負荷を平準化する |
| CloudWatch / CloudTrail | システムのエラー監視や通知およびAPIの操作履歴を記録する |
| IAM / KMS | 最小権限でのアクセス制御とデータ暗号化による強固なセキュリティを確保する |
| Step Functions | 「画像判定→分岐→通知」といった複数の処理フローを自動化して管理を容易にする |
開発環境では基本構成でも十分です。
一方で、本番運用では上記のようなサービスを組み合わせ、高負荷への耐性とセキュリティを考慮することが重要です。
Amazon Rekognitionの使用手順
ここでは、Amazon Rekognitionの使い方を誰でもイメージできるように、画面からコーディングなしで機能を動かす手順を説明します。
AWSアカウントの作成
AWSの公式サイトにアクセスします。画面の右上にある言語から日本語を選択してからアカウント作成を開始してください。
アカウントの作成は画面の指示に従って以下の情報を入力すれば作成できます。
| ・メールアドレス ・パスワード ・氏名 ・連絡先 (住所や電話番号など) ・会社名 (必要に応じて) ・クレジットカード情報 ・SMS認証用の電話番号 |
S3の準備

AWSマネジメントコンソールにアクセスします。
AWSマネジメントコンソールで「S3」を選択し、画像保管用の新しいバケットを作成。任意のバケット名とリージョンを指定します。
必要に応じてアクセス権限やバージョニング、暗号化オプションを設定すれば完了です。
分析する画像のアップロード

AWSマネジメントコンソールで作成したS3バケットを開きます。
「アップロード」ボタンから画像ファイルを選択してアップロードします。ドラッグ&ドロップやファイル選択で複数画像も一度に指定することが可能です。
アップロード後は、バケット内の「オブジェクト」一覧から画像の保存を確認できます。
Amazon Rekognitionのコンソールで分析を実行

AWSコンソールで「Amazon Rekognition」を選択し、画像分析のメニューを選びます。
S3に保存した画像オブジェクトを指定し、ラベル検出や顔認識などの分析を実行。
分析後は結果画面に検出されたラベル・信頼度スコア・その他の属性情報が表示されます。
Python (Boto3) でAmazon Rekognitionを呼び出す最小コード例
ここでは、Amazon RekognitionのAPIを呼び出す最小構成のサンプルコードを紹介します。コードは、S3に保存された画像をAmazon Rekognitionで分析し、検出されたラベル (物体やシーン) を出力するサンプルです。
Lambda関数として実装すれば、画像アップロードをトリガーに自動処理を実行できます。開発環境での動作確認にも利用できるシンプルな例となります。
| import boto3 def main () : # 1. 準備:分析対象の画像とバケットを指定 photo = ‘example.jpg’ bucket = ‘my-s3-bucket-name’ # 2. クライアントの作成:Amazon Rekognitionサービスを利用する準備 client = boto3.client (‘rekognition’) # 3. API呼び出し:detect_labels (ラベル検出) を実行 response = client.detect_labels ( Image={‘S3Object’: {‘Bucket’: bucket, ‘Name’: photo}}, MaxLabels=10, MinConfidence=70 ) # 4. 結果の出力 print (f”Detected labels for {photo}”) for label in response[‘Labels’]: print (f”{label[‘Name’]}: {label[‘Confidence’]:.2f}”) if __name__ == “__main__”: main () |
サンプルコードをベースに、検出結果をDynamoDBに保存したり、CloudWatchで処理状況を監視したりすることで、本番運用にも拡張できます。
Amazon Rekognitionのセキュリティと法的注意点(個人情報保護法・GDPR)

画像認証で扱う生体情報 (顔など) のセキュリティとプライバシーの保護は、重要な非機能要件です。AWSが提供するセキュリティ機能と、ユーザーが遵守すべき法的責任について解説します。
個人情報保護法と利用ルール
顔認識データは、「個人情報保護法」において厳格な管理が求められており、Amazon Rekognitionを用いて顔認証システムを構築する場合、以下の対応が大切です。
| ・顔データを収集・利用する場合は、何の目的で利用するのか (セキュリティ管理や本人確認など) を明示し、利用者や対象者本人に通知・掲示等を検討する ・顔認識データ取得時は、ケースにより要件が異なるため、目的の通知/公表・適切な同意取得・社内規程整備が重要となる ・収集した顔データ・個人情報の第三者提供は、利用形態や契約、委託関係の整理で変わるため、法務部門や専門家へ相談する |
※詳しくは個人情報保護法をご確認ください。
AWSはクラウドのセキュリティ (インフラ、物理設備、OS層) に責任を持ちます。一方で、クラウド内のデータの暗号化やアクセス権限、法令遵守といったセキュリティは運用側 (利用者) の責任となります。(責任共有モデル)
また、顔認識データの扱いは、利用者責任となることを意識した対応が重要です。
データ保存場所(リージョン選択)とデータ越境リスク
Amazon Rekognitionを利用する際は、収集した画像データをどの国のサーバーに保存するかは慎重に判断する必要があります。これは「データ主権(Data Sovereignty)」と呼ばれ、個人情報がどの国の法律に従うかを左右するためです。
データ所在地に関する要件 (契約条件・業界規制・社内規程など) がある場合は、要件に応じてリージョンを選定することが大切です。多くの日本企業や自治体では、「個人情報は日本国内のサーバーに保存すること」をセキュリティポリシーや契約で定めているケースがあります。その場合は、アジアパシフィック (東京) リージョンが選択肢の一つとなります。
もし米国リージョンに保存・送信した場合、データを国外に移転した扱いとなり、以下のようなコンプライアンス上のリスクが考えられます。
| ・個人情報保護法における「外国第三者提供」扱い ・追加の説明義務や同意取得が必要 |
また、EU域内で取得された個人が識別できる画像データを扱う場合は、GDPR(EU一般データ保護規則)の適用対象となる可能性があります。特に、画像に人物の顔など識別可能な情報が含まれる場合は「個人データ」とみなされ、EU域外へのデータ転送には厳格な要件が設けられています。
最終的なリージョン選定やデータ越境の可否については、契約条件や適用法規制を踏まえ、法務部門や専門家と確認した上で判断することが大切です。
AWSにおけるセキュリティ設定のBest Practice
Amazon Rekognitionを安全に利用するためには、IAM・暗号化・監査ログという3つの観点からベストプラクティスを適用することが重要です。
IAM
IAMを用いて最小権限の原則を徹底します。
Amazon Rekognitionを実行するユーザーやLambdaには、特定のS3からの読み取りやAmazon Rekognitionの実行といった、業務に必要な最低限の権限のみを許可するポリシーを適用します。
データの暗号化
画像データの暗号化による保護も重要です。
S3に保存する画像データは、SSE-S3 (標準的な暗号化) やSSE-KMS (高度な暗号化) を利用して必ずサーバーサイド暗号化を有効にします。特にSSE-KMSを利用すれば、暗号鍵における利用履歴の監査も可能です。
また、通信経路においても、VPCエンドポイントを活用することでインターネットを経由せずにAWS内部ネットワークだけで通信を完結させ、強固なセキュリティを実現できます。
監査ログ
最後に、AWS CloudTrailによる監査体制を確立します。
「いつ」「誰が」「どの画像に対して」操作を行ったかをすべて記録・保存しておくことで、万が一の情報漏洩や不正利用の疑いが生じた際に、迅速な追跡調査が可能となります。
Amazon Rekognitionの5つのユースケースと活用事例
Amazon Rekognitionの機能は汎用性が高く、小売や製造、メディアや公共など、あらゆる業界でビジネス価値を生み出しています。
Amazon Rekognitionの代表的なユースケース例は、次の通りです。
| ユースケース例 | 活用領域例 | 導入メリット |
|---|---|---|
| 監視カメラの侵入検知・人物追跡 | 防犯・施設管理 | 誤検知削減・監視自動化 |
| 工場ラインの不良品検知・PPE判定 | 品質管理・安全管理 | 検査自動化・作業品質安定 |
| 大量写真データから人物検索 | 写真管理・販売システム | 検索高速化・顧客体験向上 |
| 商品画像の属性分類・タグ付与 | EC/メディア管理 | タグ付与自動化・検索性改善 |
| UGC不適切画像モデレーション | UGCサービス・SNS・不動産サイト | 投稿審査効率化・リスク低減 |
以下では、一覧で挙げたユースケースについて、より具体的な内容と実際の活用事例を紹介します。
ユースケース1: 監視カメラの侵入検知・人物追跡
監視映像にAI分析を組み合わせることで、人物検知・行動判定・異常検知を自動化できます。誤検知削減や警備業務の効率化に繋がり、防犯・施設管理で特にニーズの高い領域です。
▼活用事例:3xLOGIC
| 3xLOGICは、商用電子セキュリティシステムのリーダーです。同社は、企業、病院、学校、政府機関に商用セキュリティシステムと管理されたビデオモニタリングを提供します。管理されたビデオモニタリングは、3xLOGIC の顧客にとって包括的なセキュリティ戦略の重要なコンポーネントです。「フィールドには 50,000 台を超えるアクティブなカメラがあり、その多くは新しく高価なカメラモデルの高度な分析が行われていないため、3xLOGIC は毎日誤警報の課題に対処しています」と、3xLOGIC の製品およびソリューション部門の CTO である Charlie Erickson 氏は述べています。「コンピュータビジョンモデルの構築、トレーニング、テスト、および保守は、リソースを大量に消費し、学習曲線が非常に大きくなります。Amazon Rekognition Streaming Video Events を使用すると、API を呼び出して、結果をユーザーに表示するだけです。非常に使いやすく、精度も抜群です」 引用: Amazon Rekognition のお客様 | 3xLOGIC |
ユースケース2: 工場ラインの不良品検知・PPE判定
製造現場では、印字確認や外観検査、安全装備(PPE)の着用判定など、人手依存の検査作業を自動化できます。作業品質の均一化と、生産効率・安全性向上が期待できるユースケースです。
▼活用事例:味の素食品株式会社
| 味の素食品株式会社では、製品の写真から自動で賞味期限を読み取る機能を実装しました。これにより、工程管理における賞味期限印字の正誤確認 (指図通りの賞味期限を印字しているか) の作業品質の向上と作業負荷軽減を実現しています。 引用: 味の素食品株式会社の AWS 事例「Amazon Rekognition を用いた製品の賞味期限検出システム」のご紹介 |
ユースケース3: 大量の写真データから特定人物の検索・マッチング
顔認識を活用することで、大量画像の中から特定人物のみを高速検索できます。学校行事写真、イベント写真販売、CRM用途など「個別写真検索」の効率化に適しています。
▼活用事例:千株式会社
| 千株式会社には、過去にユーザーが購入した写真や、ユーザーから当社のプラットフォームにアップロードされた写真の膨大なコレクションがあります。このコレクションの中で特定のユーザーのお子様の写真を検索する必要があります。Amazon Rekognition を使用するようになってから、保護者の方が数万枚の写真の中からお子様の写真を簡単に見つけることができるようになりました。Amazon Rekognition では大量の写真が非常に高速かつ正確に処理されるため、保護者の方は探している写真を簡単に見つけることができ、満足されています。その結果、コンバージョン率が向上しました。 引用: Amazon Rekognition のお客様 | 千株式会社 |
ユースケース4:商品画像の属性分類・タグ自動付与
ECやメディア企業では、画像メタデータのタグ付けを自動化することで、検索性改善・商品管理効率化を実現できます。人手作業からAI分類へ置き換えることで、運用コスト削減にも寄与します。
▼活用事例:Scripps Networks
| 手作業によるメタデータのタグ付けは時間がかかり、面倒です。自動化によって、生産性と効率を大幅に向上させることができます。Amazon Rekognition では、さまざまな自動メタデータタグ付けプロセスを使用して価値を迅速かつ効率的に付加できるようになり、当社またお客様が画像や動画セグメントをより簡単に見つけることができます。これにより当社は、サイクルタイム、生産性、効率を向上させ、収益の機会を増やすことができます。 引用: Amazon Rekognition のお客様 | Scripps Networks |
ユースケース5:UGCの不適切画像モデレーション
ユーザー投稿型サービスでは、アップロード画像に不適切コンテンツが含まれていないか事前チェックが必要です。自動モデレーションにより、プラットフォームの健全性維持を効率化できます。
▼活用事例:CoStar
| 当社のプラットフォームにアップロードされた画像が当社のエンドユーザー契約の規定に準拠しており、不適切なコンテンツが含まれていないことが不可欠です。Amazon Rekognition の Content Moderation API により、アップロードされたすべての画像を自動的に分析するソリューションを簡単に構築できるようになりました。これにより、高価値の製品をお客様に効率的に提供できるようになりました。Amazon Rekognition は、事前にトレーニングされた一連のコンピュータビジョン API を提供します。これは、コンテンツモデレーション、テキスト検出、オブジェクト検出とともに、受け取った画像をより見つけやすくし、コミュニティをよりインクルーシブにすることで、提供製品をさらに改善するのに役立ちます。 引用: Amazon Rekognition のお客様 | CoStar |
|---|
Amazon Rekognition とGoogle Vision / Azure AI Vision / 自前モデルの比較

導入を検討する際は、他社のAIサービスや自前の開発と比較することが大切です。
それぞれの強みと弱みを理解し、適切な選択を行うための指針を示します。
精度比較:標準モデル vs 文脈理解の強さ
AWS・Google・Azureの3大クラウドは、いずれも高機能な画像認識AIを提供しています。学習データの背景や開発思想により、得意とする領域 (個性) には明確な違いがあります。
精度は、用途・データ・条件によって変動するため、自社データを使いPoC評価を行うことが大切です。
ここでは各社の主な特徴を機能別に比較します。
| 比較項目 | Amazon Rekognition | Google Cloud Vision API | Azure AI Vision |
|---|---|---|---|
| 顔認識・人物分析 | ・精度評価: 高い傾向がある ・特徴: 感情、年齢、PPE (装備) など属性分析が詳細。顔認証にも強い ・適性: セキュリティ監視や顧客分析 | ・精度評価: 標準的な傾向がある ・特徴: 顔検出 (位置・感情) は可能だが、プライバシー配慮により個人の特定 (顔認証) 機能は非提供 | ・精度評価: 高い傾向がある ・特徴: 感情認識を含め機能が充実しており、バランスが良い |
| ラベル検出 (文脈) | ・精度評価: 実用性が高い傾向がある ・特徴: 車、犬、家具など、具体的な物体の検出に強みあり | ・精度評価: 極めて高い傾向がある ・特徴: 膨大な学習データを活かし、観光地 (ランドマーク) の特定や画像の文脈理解に強い | ・精度評価: 汎用的な傾向がある ・特徴: Office製品などマイクロソフトのエコシステムとの連携に優れている |
| 日本語OCR | ・精度評価: シーン内文字に限定される傾向がある ・特徴: 看板などの風景文字向け (文書読取や手書きにはAmazon Textractの併用が推奨) | ・精度評価: 高い傾向がある ・特徴: 翻訳技術の応用により、日本語の認識精度は他社をリードする水準 | ・精度評価: 高い傾向がある ・特徴: 特に「手書き文字」の認識精度において高い定評あり |
| モデレーション | ・特徴: 専用APIにより、詳細なカテゴリ分類 (露出や暴力など) が可能で制御しやすい | ・特徴:セーフサーチ検出として機能提供 | ・特徴:コンテンツモデレーターとして提供 |
人物分析やセキュリティ監視の分野では、顔認証や属性分析に強いAmazon Rekognitionが優位性があります。一方、Google Cloud Vision APIは日本語OCRやランドマーク検知といったWeb上の広範な知識や言語処理が絡む領域に強みがあるものの、特定の個人を識別する顔認証 (Facial Recognition) 機能は公式にサポートされていない点に注意が必要です。また、Azureは手書き文字認識などで優位といえます。
したがって「人を監視・分析したいならAWS」のように、認識対象の性質に合わせてAPIを選ぶことがポイントといえます。また、各サービスの最新情報や機能制限については、公式ドキュメントで確認することが大切です。
APIの使いやすさ:導入のしやすさで比較
画像認識AIを選定する際には、精度の高さと同じくらい、既存システムといかにスムーズに連携できるかという点が重要です。APIの使い勝手やエコシステムとの親和性は、開発スピードと運用コストに直結します。
AWS・Google Cloud・Azure・自前モデルについて、開発・導入のしやすさを比較しました。
| 比較項目 | APIの使いやすさ・特徴 | 推奨される判断基準 |
|---|---|---|
| Amazon Rekognition | ・S3連携に強み ・画像をS3に置くだけで自動起動するサーバーレス構成 (Lambda) が容易 ・AWSインフラとシームレスに統合可能 | ・AWS利用者向け ・既存のAWS環境との統合を重視する場合 ・インフラ構築工数を最小化したい場合 |
| Google Cloud Vision API | ・SDKとレスポンスが柔軟 ・主要言語のSDKが充実しており導入がスムーズ ・JSON構造が扱いやすく、アプリへの組み込みが容易 | ・開発柔軟性重視 ・多言語対応やSDKの充実度を求める場合 ・データの加工しやすさを優先する場合 |
| Azure AI Vision | ・Microsoft製品との統合 ・Office 365やActive Directoryとの連携が強力 ・Cognitive ServicesとしてAPI体系が統一されている | ・Microsoft環境向け ・社内システムがMS製品中心の場合 ・既存のセキュリティポリシーと統合したい場合 |
| 自前モデル | ・自由だが実装負荷が大 ・API設計、サーバー構築、セキュリティ対策がすべて自前 ・専門人材 (MLエンジニア) が不可欠 | ・高度なカスタマイズ ・既存APIでは実現できない特殊要件がある場合 ・開発期間とコストをかけてでも独自性を出す場合 |
機能単体の優劣で選ぶのではなく、自社の現在の技術スタックに合うかが選定ポイントです。
例えば、既にAWSでシステムを運用している場合、Google Vision APIを採用すると認証やデータ転送の手間が余計にかかる可能性があります。
まずは、メインで使っているプラットフォーム (AWS・Google・Azure) を軸に検討しましょう。どうしても特殊な要件がある場合のみ自前モデルを検討するというアプローチが、リスクとコストを抑えられる選択肢です。
学習不要度:標準モデル vs カスタムモデルの柔軟性
画像認識AIを検討する際には、「標準APIだけで目的を満たせるか」または「自社固有の対象を認識させるために追加学習が必要か」を判断することが重要です。
AWS・Google・Azureではいずれも学習済みモデルを提供しており、基本的な画像認識であれば学習なしで利用できます。
一方で、より精度要件が高い場合や、既存サービスでは対応できない特殊な分類が必要な場合、「自動学習(AutoML)によるカスタムモデル」または「完全に自社で構築する独自モデル」のどちらかを検討することになります。
以下は、標準API・カスタムモデル・自前モデルの違いを整理した比較早見表です。
どこまで学習不要で使えるかを判断するための参考としてご活用ください。
| 観点 | Amazon Rekognition | Google Cloud Vision | Azure AI Vision | 自前モデル |
|---|---|---|---|---|
| 標準モデルのみで使える範囲 | ◎(顔認証・物体検知・モデレーションに強い) | ◎(ランドマーク・OCRに強い) | ◎(OCR・分析全般を幅広く) | × |
| 独自対象の学習対応 | Custom Labels(少量データでOK) | AutoML Vision | Custom Vision ※利用時は2028/9/25で退役予定のため、移行計画が必要です。 | ○(自由度高い) |
| 必要なデータ量 | 少量(数十〜数百枚) | 少量〜中量 | 少量〜中量 | 多い(数千〜数万枚以上) |
| 導入難易度 | 低い(UIとAPIで完結) | 低〜中 | 低〜中 | 高い(MLエンジニア必須) |
| 向いている用途 | 監視・品質検査・顔認証 | 画像検索・翻訳・観光用途 | エンタープライズDX | 特殊用途・研究開発 |
コスト比較 (従量課金モデルの違い)
Amazon RekognitionやGoogle Cloud Vision API、Azure AI Visionの3大クラウドサービスは、いずれも初期費用不要の「従量課金制」を採用しており、スモールスタートが可能です。
しかし、無料枠の条件や大量利用時の割引制度、カスタムモデル利用時の課金体系には各社の特徴が現れます。
以下に、自前モデルでの運用も含めたコスト特性を比較しました。
| 比較項目 | 料金体系・コスト特徴 | コスト面での選定ポイント |
|---|---|---|
| Amazon Rekognition | ・従量課金制 (明確な料金体系) ・無料利用枠あり (期間・枚数制限あり) ・ボリュームディスカウントあり (処理量に応じた段階割引) ・Custom Labelsはモデル稼働時間による課金 | ・スモールスタート〜中規模 ・無料枠が手厚く、初期コストを抑えたい場合 ・必要な時に必要な分だけ使う柔軟性を重視する場合 |
| Google Cloud Vision API | ・従量課金制 (段階的割引あり) ・無料利用枠あり ・処理量が増えるほど単価が下がる ・AutoML Visionは学習時間とノード時間に応じた課金 | ・データ分析基盤との統合 ・利用量が増えるほど単価が下がる段階料金を活用したい場合 ・BigQuery等と連携し、データ処理全体のコスト効率を高める場合 |
| Azure AI Vision | ・従量課金 + コミットメント割引 ・一定量の事前確約 (コミット) で割引適用 ・ハイブリッド特典等の併用で大幅割引の可能性 | ・大規模・長期利用 ・利用量が予測可能で、長期契約による大幅割引を狙う場合 ・既存のMicrosoftライセンス資産を活用したい場合 |
| 自前モデル | ・固定費 (GPUサーバー代) ・推論サーバーの常時稼働費や学習コストが発生 ・運用保守コストも必要 | ・超大規模・特殊要件 ・クラウドAPIでは割高になるほどの超大量リクエストがある場合 ・コスト予測の難しさよりも、完全な柔軟性を優先する場合 |
立ち上げ初期やスポット利用であれば、無料枠が手厚く料金がシンプルなAmazon Rekognitionが有利です。
一方で、事業が拡大し月間の処理枚数が数百万〜数千万規模になる場合は、段階的な割引が効くGoogle Cloudや、事前コミットによる割引が強力なAzureへの移行や併用を検討する必要があります。
自前モデルは柔軟性に優れているものの、コスト管理の難易度が高いため、明確な勝算がある場合以外はクラウドAPIの利用が推奨されます。
具体的な料金や無料枠の詳細については、リージョンや為替レート、プランの改定により変動します。最新情報は、各社の公式料金ページ (AWS公式・Google公式・Azure公式)で確認することが大切です。
まとめ
Amazon Rekognitionは、一部の先端企業だけのものではありません。専門的な機械学習の知識がなくても、API一つで世界最先端の「目」をビジネスに導入できる、強力なツールといえます。
まずは無料利用枠を活用し、マネジメントコンソール上でご自身の画像をアップロードしてデモを触ってみることから始めてみてはいかがでしょうか。
クラウドサーバーの構築支援なら、国内25,000人以上 (※1) の技術者を擁し、大手企業を中心に2,555社との取引実績 (※2) を持つ株式会社テクノプロにお任せください。AWS導入の準備段階からビジネス設計、本稼働、運用まで、一括して任せることができます。
※1: 2024年6月末時点
※2: (株) テクノプロ及び (株) テクノプロ・コンストラクション 2024年6月末時点
監修者

テクノプロ・ホールディングス株式会社
チーフマネージャー
中島 健治
2001年入社
ITエンジニアとして25年のキャリアを持ち、チーフマネージャーとしてテクノプロ・エンジニアリング社にて金融・商社・製造業など多業界でのインフラ基盤構築に従事してきた。2008年から2024年まで、オンプレミス環境でのストレージ・サーバ統合基盤の設計・構築を手掛け、特に生成AI・データ利活用分野のソリューション開発実績が評価されている。現在は技術知見を活かしたマーケティング戦略を推進している。






