クラウド上でシステムを構築する際、データベースの選定はシステムの品質やレスポンスを左右する重要な構成要素です。特にAWSは、リレーショナルデータベース(RDB) からNoSQL、インメモリ、データウェアハウス (DWH) まで、複数サービスを提供しており、用途やワークロード (システムが処理すべき仕事のまとまり、またはその負荷) に応じて複数のデータベースから最適な選択ができます。
本記事では、AWSが提供する主要なデータベースの種類と特徴を体系的に整理したうえで、特性に基づいた選定方法・具体的なユースケース・料金体系・導入時に押さえておくべき注意点までを網羅的に解説します。
AWS環境にデータベースを導入する際は、世界規模の製造メーカーや大手IT企業など多くの企業のシステム構築を支援してきた株式会社テクノプロにご相談ください。
システム構築に強みを持つ株式会社テクノプロなら、AWS環境の導入に向けた準備段階から設計・開発・運用の各段階に応じて、経験豊富なエンジニアが効率的に支援を行い、費用対効果の高いサービスを実現します。
テクノプロはAWSの構築から運用まで幅広く支援しています
AWS データベースの種類と主要サービス比較表

AWSのデータベースは、Amazon RDSやAmazon Aurora、Amazon DynamoDBなど、用途に応じて選択できる多様なサービスを提供しています。
| 主な用途 | サービス | 分類 |
|---|---|---|
| 業務システム | Amazon RDS | リレーショナルDB |
| 高負荷Web・SaaS | Amazon Aurora | |
| 大規模アプリ | Amazon DynamoDB | NoSQLデータベース |
| MongoDB移行 | Amazon DocumentDB | |
| セッション管理 | Amazon ElastiCache | インメモリDB |
| 高速+永続 | Amazon MemoryDB | |
| BI分析基盤 | Amazon Redshift | データウェアハウス |
| ログ分析 | Amazon Athena | |
| 全文・意味検索 | Amazon OpenSearch Service | 目的特化型DB |
| 関係性分析 | Amazon Neptune | |
| IoT・ログ | Amazon Timestream | |
| 分散SQL基盤 | Amazon Aurora DSQL |
ここでは、RDB・NoSQL・インメモリ・DWH・目的特化型の5つのカテゴリに分けて、各サービスの特徴を解説していきます。
リレーショナルデータベース (RDB) | DBの王道
リレーショナルデータベースは、データをテーブル (表) 形式で管理し、テーブル同士をキーで関連付けることで複雑なデータ構造を整理できるデータベースです。
AWSでは、RDBをクラウド上で手軽に構築・運用できるマネージドサービス (インフラの管理・運用をAWSが代行するサービス) として、Amazon RDSとAmazon Auroraを提供しています。
Amazon RDS
Amazon RDSは、クラウド上でRDBのセットアップ・運用・スケーリング (システムの処理能力を拡張・縮小) を簡単に行えるフルマネージドサービスです。MySQL・PostgreSQL・Oracle・SQL Serverなどの主要なDBエンジンに対応しており、オンプレミス環境で使い慣れたエンジンをそのままAWS上で利用できます。
主な特徴は以下の通りです。
| ・AWSコンソールから数クリックでDBインスタンスを起動可能 ・バックアップの自動取得やパッチ適用をAWSが代行し、運用負荷を大幅に削減 ・マルチAZ配置による自動フェイルオーバー (障害発生時に待機系へ自動で切り替わる仕組み) で高い可用性を維持 |
既存のオンプレミスDBをそのままクラウドへ移行したいケースや、DBエンジンの選択肢を幅広く確保したい場合に向いているサービスです。
Amazon Aurora
Amazon Auroraは、AWSがクラウド環境向けに独自開発した高性能RDBエンジンです。MySQLおよびPostgreSQLとの完全な互換性を備えています。標準的なMySQLやPostgreSQLを大幅に上回るスループット (単位時間あたりに処理できるデータ量) を実現しており、高負荷なWebアプリケーションやSaaS基盤に向いています。
| サーバーレス対応 | Aurora Serverlessによりトラフィック変動に応じた自動スケーリングに対応 |
|---|---|
| 互換性 | MySQL・PostgreSQLと互換性がある |
| パフォーマンス | 標準的なMySQLやPostgreSQLを大幅に上回るスループット |
| ストレージの冗長性 | 複数のAZにまたがりデータを自動でレプリケーション (複製) する構成 |
| リードレプリカ | 複数のリードレプリカ(読み取り専用の複製DB)に対応し、読み取り負荷の分散とフェイルオーバー高速化が可能 |
Amazon Auroraは、商用データベースに匹敵する性能を、オープンソースDBに近いコストで実現できる点が強みです。
NoSQLデータベース|圧倒的拡張性
NoSQLは、RDBのようなテーブル形式にとらわれず、柔軟なデータ構造で大量のデータを高速に処理できるデータベースです。
固定的なスキーマ (データの構造定義) を持たないため、アプリケーションの要件変化にも柔軟に対応できます。サーバーを追加して処理能力を高める水平スケーリング (サーバーの台数を増やして処理を分散する方式) に優れており、大規模アプリケーションやリアルタイム処理が求められるシステムに向いています。
AWSでは、NoSQLのマネージドサービスとして、Amazon DynamoDBとAmazon DocumentDBを提供しています。
Amazon DynamoDB
Amazon DynamoDBは、キーバリュー型 (キーと値のペアでデータを管理する形式) とドキュメント型 (JSONなどの構造でデータを管理する形式) の両方をサポートするフルマネージドNoSQLデータベースです。
あらゆる規模で一貫した低レイテンシー (応答遅延) のパフォーマンスを提供し、大規模なアプリケーション基盤として広く採用されています。
主な特徴は以下の通りです。
| サーバーレス対応 | 容量管理やインフラ運用が不要 |
|---|---|
| 自動スケーリング | トラフィックに応じてキャパシティを自動調整 |
| 高可用性 | 複数のAZにデータを自動レプリケーションし、耐久性を確保 |
| 課金体系 | オンデマンドモード (リクエスト数に応じた従量課金) とプロビジョニングモード (事前に処理能力を確保する定額課金) の2種類から選択可能 |
ゲーム・IoT・広告配信・ECサイトなど、大量のリクエストを低遅延で処理する必要があるケースに向いています。
Amazon DocumentDB
Amazon DocumentDBは、MongoDB互換のフルマネージド型ドキュメントDB (JSONなどの柔軟なデータ構造を扱えるデータベース) です。既存のMongoDBアプリケーションで使用しているドライバーやツールをほぼそのまま利用でき、コード変更を最小限に抑えた移行を行えます。
| サーバーレス対応 | DocumentDB Serverlessにより、ワークロードに応じた自動スケーリングが可能 |
|---|---|
| 互換性 | MongoDB APIおよびドライバーと互換性があり、既存資産を活用した移行が容易 |
| パフォーマンス | 複数のAZにまたがるレプリケーションと自動フェイルオーバーに対応 |
| 可用性 | オンデマンドモード (リクエスト数に応じた従量課金) とプロビジョニングモード (事前に処理能力を確保する定額課金) の2種類から選択可能 |
オンプレミスや他クラウドで運用中のMongoDBワークロードをAWSに移行したい場合や、JSONデータを柔軟に管理したいケースに向いているサービスです。
インメモリデータベース |高速レスポンスを実現
インメモリデータベースは、データをメモリ上に格納するデータベースです。ディスクI/Oが発生しないため、従来のディスク型データベースより応答速度に優れています。インメモリデータベースは、セッション管理やリアルタイムランキング、頻繁にアクセスされるデータのキャッシュなど、低レイテンシーが求められるケースに向いています。
Amazon ElastiCache
Amazon ElastiCacheは、Valkey・Memcached・Redis OSSと互換性を持つフルマネージド型のインメモリキャッシュサービスです。マイクロ秒単位のレイテンシーで1秒あたり数億回のオペレーションに対応でき、データベースへのアクセス負荷を軽減しつつアプリケーションの応答速度を向上させます。
| サーバーレス対応 | ElastiCache Serverlessにより、インフラ設定なしで高可用なキャッシュを即座に作成可能 |
|---|---|
| キャッシュ用途 | 頻繁にアクセスされるデータをメモリにキャッシュし、Amazon RDSやAmazon AuroraなどのバックエンドDBの読み取り負荷を軽減 |
| 高可用性 | マルチAZ構成で障害時には自動フェイルオーバーで切り替えが可能 |
| 互換性 | Valkey・Memcached・Redis OSSのAPIと完全互換のため、既存のツールやコードをそのまま利用可能 |
Amazon ElastiCacheはWebアプリケーションのセッション管理やリアルタイムランキング、レコメンデーションエンジンなど、頻繁なデータ読み取りが発生するシステムに向いています。
Amazon MemoryDB
Amazon MemoryDBは、Valkey・Redis OSSと互換性を持つ耐久性に優れたフルマネージド型インメモリデータベースです。Amazon ElastiCacheがキャッシュ用途を主な目的としているのに対し、Amazon MemoryDBはマルチAZトランザクションログによるデータの永続化を備えており、プライマリデータベース (メインのデータ保存先) としても安全に利用できます。
| パフォーマンス | インメモリならではの高速な読み書きを実現 |
|---|---|
| データの永続性 | マルチAZのトランザクションログにデータを永続的に保存し、障害時もデータ損失なく復旧が可能 |
| スケーラビリティ | 突発的で大量のリクエストを処理しつつ、大規模アプリケーションにも耐えうる大きなデータ容量まで拡張可能 |
| マルチリージョン対応 | MemoryDB Multi-Regionにより、複数リージョンにまたがるアクティブ構成を実現 |
マイクロサービスアーキテクチャにおけるプライマリDBや、キャッシュと永続DBを一つに統合したいケースに向いているサービスです。
データウェアハウス (DWH)・分析サービス | ビッグデータ分析の基盤
データウェアハウスは、社内の複数のシステムから集めた大量のデータを一元的に蓄積し、分析やレポーティングに活用するための専用DBです。通常のリレーショナルデータベースがリアルタイムのトランザクション処理を得意とするのに対し、データウェアハウスは大量データの集計・分析処理に最適化されています。列指向ストレージや超並列処理といった技術により、テラバイトからペタバイト規模のデータに対しても高速にクエリを実行できるのが特長です。
Amazon Redshift
Amazon Redshiftは、AWSが提供するフルマネージド型のクラウドデータウェアハウスサービスです。列指向ストレージと超並列処理を組み合わせることで、ペタバイト規模のデータに対しても高速なクエリ実行を実現します。
| サーバーレス対応 | Redshift Serverlessにより、クラスターの管理やチューニングが不要になり、使用した分だけの従量課金で運用コストの最適化が可能 |
|---|---|
| 高速な分析処理 | 列指向ストレージ (カラムナストレージ) と高度なデータ圧縮により、ディスクの読み書きを最小化しつつ高速な集計・分析が可能 |
| スケーラビリティ | ペタバイト規模のデータを処理でき、ノードの追加やRedshift Serverlessの自動スケーリングにより、ワークロードに応じた柔軟な拡張に対応 |
| AWSサービス連携 | Amazon S3・AWS Glueなどと統合でき、データの取り込みから可視化までをシームレスに構築可能 |
Amazon Redshiftは、売上分析やBI (ビジネスインテリジェンス) ダッシュボード、マーケティングデータの集計など、大量の構造化データを定期的に分析するケースに向いています。
Amazon Athena
Amazon Athenaは、Amazon S3に保存されたデータに対して標準SQLで直接クエリを実行できるサーバーレス分析サービスです。事前にデータをロードしたりインフラを構築したりする必要がなく、Amazon S3上のデータをそのまま分析に活用できます。
| サーバーレス・ゼロETL | インフラの構築や分析用DBへのデータ移行処理(ETL)が不要で、S3に置かれたデータに対してクエリを実行するだけで利用を開始できる |
|---|---|
| 幅広いデータ形式 | CSV・JSON・Parquet・ORC・Avroなど、多様なデータフォーマットに対応 |
| 従量課金 | スキャンしたデータ量に対してのみ課金が発生するため、利用頻度が低いケースでもコストを抑えやすい |
| AWS Glue連携 | AWS Glueのデータカタログと統合することで、データの自動検出やスキーマ管理を効率化できる |
Amazon Athenaは、ログ分析やアドホック (その場限りの) データ調査、S3データレイクに蓄積された非定型データの探索的分析に適したサービスです。
目的特化型データベース|グラフ・時系列・検索・AI活用
AWSでは、リレーショナルデータベース・NoSQL・インメモリ・データウェアハウスといった汎用的なデータベースのほかに、特定のユースケースに最適化された「目的特化型」のデータベースサービスも提供しています。
データの構造やアクセスパターンに応じて適切なサービスを選択することで、パフォーマンスとコストの両面で優れた結果を得られます。
Amazon OpenSearch Service
Amazon OpenSearch Serviceは、オープンソースのOpenSearchをベースにしたフルマネージド型の検索・分析基盤 (ベクトル検索にも対応した検索・分析サービス) です。テキスト検索やログ分析、リアルタイムモニタリングなど、大量のデータから素早く必要な情報を検索・可視化するケースに向いています。
| サーバーレス対応 | OpenSearch Serverlessにより、クラスターのサイジングやチューニングを気にせず利用を開始できる |
|---|---|
| 全文検索 | ECサイトの商品検索や社内ドキュメント検索など、大規模なテキストデータに対する高速な検索機能を提供 |
| ログ分析・モニタリング | アプリログやインフラメトリクスをリアルタイムで収集・分析し、OpenSearch Dashboardsで可視化が可能 |
| ベクトル検索 | 高次元ベクトルの保存と検索に対応しており、Amazon Bedrockなどの生成AIサービスと連携したRAG (検索拡張生成) アプリケーションの構築にも活用可能 |
Amazon OpenSearch Serviceは、テキスト検索やログ分析、リアルタイムモニタリングなど、大量のデータから素早く必要な情報を検索・可視化するユースケースに向いています。
Amazon Neptune
Amazon Neptuneは、データ間の関係性を効率的に扱うフルマネージド型のグラフデータベースサービスです。
ノード (データのエンティティ) とエッジ (ノード間の関係) でデータを表現するグラフ構造により、リレーショナルデータベースでは複雑になりがちな関連データのクエリを高速に実行できます。
| サーバーレス対応 | Neptune Serverlessにより、ワークロードに応じてキャパシティを自動調整し、ピーク時と比較して大きなコスト削減が可能 |
|---|---|
| 高速なリレーションシップクエリ | 膨大で複雑なリレーションシップを高速に検索・ナビゲートでき、複数の同時クエリに対応可能 |
| 複数のクエリ言語 | OpenCypher、Apache TinkerPop Gremlin、SPARQLをサポートしており、プロパティグラフとRDFの両方のグラフモデルに対応可能 |
| 高可用性 | 複数のAZにまたがるデータレプリケーションと自動フェイルオーバーにより、高い可用性を提供 |
Amazon Neptuneは、ソーシャルネットワークの関係性分析や不正検知、ナレッジグラフの構築、レコメンデーションエンジンなど、データ同士のつながりを活用するシステムに向いています。
Amazon Timestream
Amazon Timestreamは、IoTや運用アプリケーション向けに設計されたフルマネージド型の時系列データベースサービスです。時間の経過に伴って変化するデータ (センサーの測定値、システムメトリクスなど) を効率的に収集・保存・分析する用途に特化しています。
| サーバーレス対応 | インフラの管理が不要で、データ量やクエリ負荷に応じて自動スケーリング |
|---|---|
| 高速・大規模処理 | 絶え間なく発生する膨大な時系列イベントを、一般的なデータベースと比較して圧倒的に高速かつ低コストで処理が可能 |
| 自動データ管理 | 直近のデータはメモリストアに、過去のデータは磁気ストアに自動で移動し、利用者はストアの違いを意識せずにクエリの実行が可能 |
| 組み込み分析関数 | 平滑化・近似・補間といった時系列専用の分析関数がSQLで利用でき、トレンドやパターンの特定を効率化 |
Amazon Timestreamは、IoTデバイスのセンサーデータ分析やDevOpsのインフラモニタリング、産業用テレメトリ (遠隔測定) データの収集・分析に適しています。
Amazon Aurora DSQL
Amazon Aurora DSQLは、サーバーレスの分散SQLデータベースサービスです。PostgreSQLとの互換性を持ち、従来のRDBでは難しかったグローバル規模での水平スケーリングと高可用性を両立しています。
ただし、外部キー制約の強制・一時テーブル・トリガー・PL/pgSQLなど一部の機能は非対応のため、利用前に互換性の確認が必要ですが、最小限の変更で移行できるケースもあります。
| サーバーレス対応 | プロビジョニング・パッチ適用・メンテナンスによるサービス停止時間などの運用負荷が発生しない |
|---|---|
| 実質無制限のスケーラビリティ | 読み取り・書き込み・コンピューティング・ストレージがそれぞれ独立してスケールし、データベースのシャーディングやインスタンスのアップグレードが不要 |
| 高可用性 | アクティブ構成の分散アーキテクチャにより、シングルリージョンおよび、マルチリージョンで高い可用性を実現 |
| 整合性の保証 | 分散環境においてもすべてのリージョンエンドポイントへの読み書きでトランザクションと強い整合性を保証 |
Amazon Aurora DSQLは、グローバルに展開するアプリケーションや、マイクロサービスアーキテクチャにおけるスケーラブルなプライマリDBとして注目されているサービスです。
AWSが提供するマネージドデータベースとは

AWSのデータベースサービスを活用するうえで、マネージドサービスという概念を理解しておくことは大切です。マネージドサービスのデータベースは、自社で管理するデータベースと比較して、運用負荷を大幅に削減できる特徴があります。
マネージドサービス | インフラ管理をAWSに任せるサービス
マネージドサービスとは、サーバーのプロビジョニング (サーバーのリソースを確保・設定する作業) ・OSの管理・DBソフトウェアのインストールといったインフラ運用をAWSが一括して代行するサービス形態です。
オンプレミスやEC2でデータベースを自前構築する場合、OSのインストールやパッチ適用など多くの作業を担当者が行う必要があります。一方、マネージドサービスではこれらをAWSが担うため、開発者やシステム担当者はアプリケーションの開発・改善に集中できます。
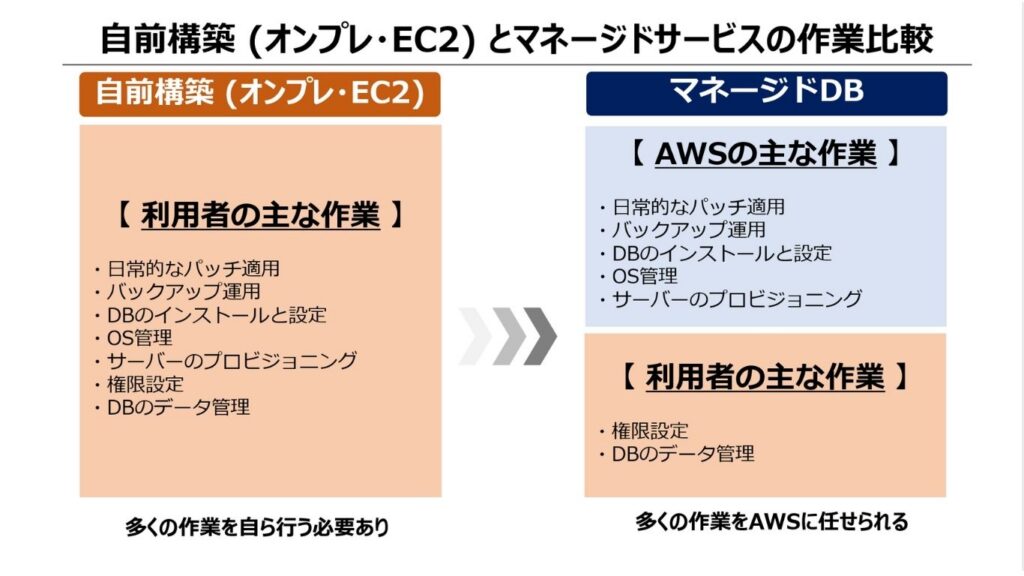
また、AWSコンソール (AWSのサービスをブラウザから操作するための管理画面) やAPIを使い簡単にデータベースを立ち上げられるため、開発スピードの向上にもつながります。
マネージドサービスのデータベースと自前構築 (EC2) の違い
AWS環境でデータベースを運用する場合、AWSが提供するマネージドサービスのデータベースを利用する方法と、EC2(AWSの仮想サーバーサービス)上にデータベースを自前で構築する方法があります。どちらを選ぶかは、運用負荷・コスト・設定の自由度のバランスによって決まります。
EC2上にデータベースを自前で構築する場合、OSのインストールと設定やDBエンジンのセットアップなど全作業の対応が必要です。これらは専門的な知識を持つエンジニアが担当することが多く、特定の担当者に運用が集中する属人化のリスクが生じやすい点も課題の一つです。
一方、AWSが提供するマネージドサービスのデータベースでは、多くの運用作業をAWSが担うため、運用コストと属人化リスクを大幅に削減できます。このことから、担当者はデータベースの設計や最適化といった本質的な業務に集中することが可能です。
ただし、EC2上への自前構築が有効な場面もあります。マネージドサービスでは対応していない特殊なDBエンジンの利用や、特定のバージョンへの固定が必要なケース、またはOSレベルまで細かく設定を制御したい場合には、EC2上への構築が選択肢になります。
2つの方式の主な違いは以下の通りです。
| 比較項目 | マネージドサービスのDB | EC2上に自前で構築したDB |
|---|---|---|
| OSパッチ適用 | AWSが自動実施 | 担当者が手動管理 |
| バックアップ | AWSが自動取得 | 担当者が設計・管理 |
| レプリケーション・冗長化 | 設定画面から簡単に構成可能 | 担当者が設計・構築が必要 |
| DBエンジンの自由度 | 提供エンジン・バージョンに制限あり | 任意のエンジン・バージョンを選択可能 |
| トータルコスト (運用・人件費含む) | 総合的に低い | 総合的に高い |
| 属人化リスク | 低い | 高い |
AWSが提供するマネージドサービスのデータベース利用が推奨されます。しかし、要件によってEC2上の自前構築も選択肢となります。
システム担当者を支える3つの自動化機能 (パッチ適用・バックアップ・冗長化)
AWSのマネージドDBでは、従来は担当者が手作業で行っていた運用作業の多くが自動化されています。
代表的な3つの自動化機能 (パッチ適用・バックアップ・冗長化) は次の通りです。
| パッチ適用 | メンテナンスウィンドウを設定することで、DBエンジンやOSのパッチをAWSが自動適用 |
|---|---|
| バックアップ | 自動スナップショットとトランザクションログ保存により、任意の時点に復元可能 |
| 冗長化 | マルチAZ配置により、別AZにスタンバイを構築し、障害時に自動フェイルオーバー |
このように、マネージドDBでは日常的な運用作業の多くがAWS側で自動化されており、担当者はアプリケーションの開発や改善に集中できます。
AWSと利用者の責任分担を明確にする「責任共有モデル」の重要性
「責任共有モデル」とは、クラウドのセキュリティについてAWSと利用者がそれぞれの責任を分担するという考え方です。
以下のように、AWSがインフラの管理を担う一方、データ保護やアクセス制御などは利用者側の責任となります。
| AWSの責任 | データセンターの物理保護・ハードウェア・ホストOS・DBエンジンのパッチ適用 |
|---|---|
| 利用者の責任 | データの保護・IAMによるアクセス権限管理・セキュリティグループ設定・アプリケーション設定 |
また、責任の分界点は利用するサービスによっても変わるため注意が必要です。マネージド度が高いサービスほど、AWSが担う範囲が広がります。
| EC2上に自前でDBを構築した場合 | ゲストOSのパッチ管理・DBエンジンの設定・バックアップまで利用者が担う |
|---|---|
| Amazon RDS | DBエンジンやOSの管理はAWSが担い、利用者はDB設定・アクセス管理に集中できる |
| Amazon DynamoDB | インフラ管理のほぼすべてをAWSが担い、利用者はデータ管理・IAM権限・暗号化方針の設定に集中できる |
AWSが提供するマネージドサービスのデータベースを活用すれば利用者の運用負荷は下がります。一方で、データやアクセス制御に関するセキュリティ責任はどのサービスを選んでも利用者側に残ります。
責任共有モデルを正しく理解し、自社が担うべき範囲を確実に対処することが、AWS環境の安全なデータベース運用では重要です。
AWSデータベースの選定方法
AWSでは複数のでーtサービスが提供されています。選定ポイントはデータ構造と活用目的・ワークロードの特性・可用性と移行のしやすさを基準に絞り込むことです。
以下は代表的な選定フローです。
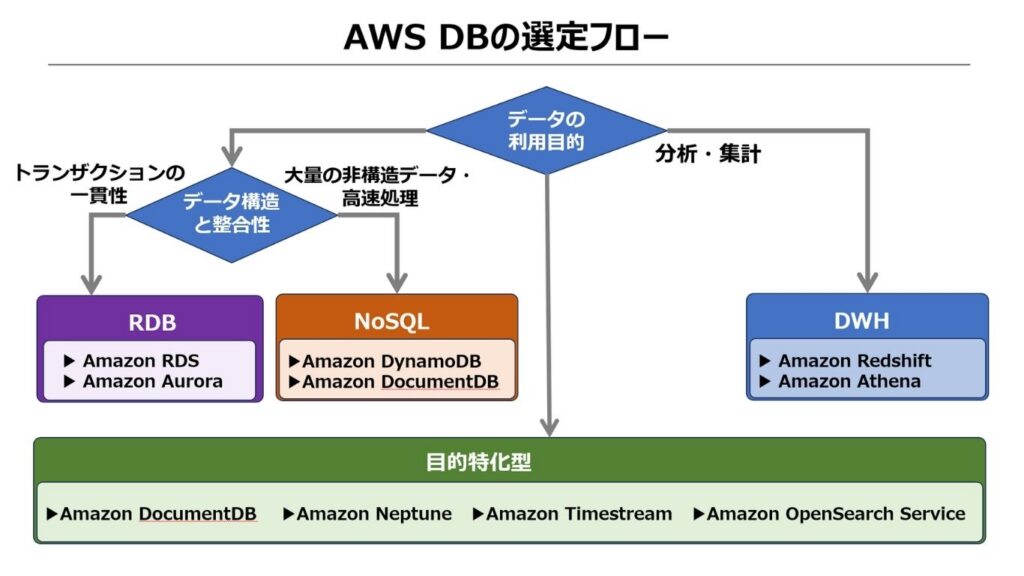
選定基準1 | データ構造と活用目的で大枠を絞り込む
最初のステップは、扱うデータの構造と、そのデータベースを何のために使うのかを明確にすることです。この段階では、以下の3つの観点を検討することでデータベースの大カテゴリを大まかに絞り込みます。
| 観点 | 向いているDBの分類 | 代表的なDBサービス |
|---|---|---|
| 決済・在庫など、トランザクションの一貫性が必要か? | リレーショナルDB (RDB) | ・Amazon RDS ・Amazon Aurora |
| ログ・センサーなど、大量の非構造化データを高速に扱うか? | NoSQLデータベース | ・Amazon DynamoDB ・Amazon DocumentDB |
| 売上集計・BIレポートなど、分析・集計が主目的か? | データウェアハウス (DWH) | ・Amazon Redshift ・Amazon Athena |
また、以下のような特殊なデータ構造には目的特化型データベースの検討も必要です。
| JSONドキュメント形式で管理したい | Amazon DocumentDB |
|---|---|
| グラフ構造 (人・物・関係性のネットワーク) を扱う | Amazon Neptune |
| 時系列データ (IoTセンサー値・サーバメトリクス) を収集・分析する | Amazon Timestream |
| 全文検索・ログ分析・AI検索 (ベクトル検索) が必要 | Amazon OpenSearch Service |
AWSは万能なデータベースは存在しないという考え方のもと、目的に合わせたデータベースの選定を推奨しています。データ構造と利用するケースを先に定義することが、最適なサービス選定の出発点です。
選定基準2 | ワークロードの特性でサーバーレスか否かを決める
データベースの大カテゴリが決まったら、次はアクセス量の変動パターン (ワークロードの特性) をもとに、サーバーレス型かプロビジョニング型かを選択します。
サーバーレス型が向いているケース
トラフィックの予測が難しく、アクセスが断続的なシステムや、開発・検証の初期フェーズにはサーバーレス型 (Amazon DynamoDB・Amazon Athenaなど) が向いています。
▼サーバーレス型が向いているケース
| ・アクセスが急増・急減するECサイト、定期レポート生成するケース ・グローバル展開のマイクロサービス ・イベント・ゲーム・IoTなど、大量リクエストが突発的に発生するケース ・スポット的なログ分析・アドホックなデータ調査 |
Aurora Serverless v2は、ワークロードに応じて細かくスケールアップ・ダウンします。リードレプリカ・マルチAZなど、多くの本番向け構成に対応しており、プロビジョニング型に近い機能を利用できます。ただし、0 ACUへの自動一時停止 (auto-pause) などの機能可否はエンジンとバージョンによって異なるため、利用前の確認が必要です。
また、サーバーレスは運用負荷が最小ですが、制限も把握しておく必要があります。
▼サーバーレスの制限事項
| コールドスタート遅延 | 一定時間のアイドル後に (コストを完全にゼロにした状態から) 再起動される際、遅延が発生する場合がある |
|---|---|
| 同時接続数の上限 | サービスごとに同時接続数の上限があるため、大量同時接続が発生するシステムでは事前の確認が必要 |
| パブリックIPの制限 | 同一VPC内からのアクセスのみ対応し、外部から直接接続できない場合がある |
プロビジョニング型が向いているケース
アクセス量が一定かつ高負荷で、安定したパフォーマンスが求められるシステムにはプロビジョニング型が向いています。
▼プロビジョニング型が向いているケース
| ・常時高負荷で大量のクエリが発生する基幹業務システム ・ピーク時の処理能力を事前に確保し、リザーブドインスタンス割引を活用したいケース ・安定稼働が続く本番環境でコストを最小化したいケース |
プロビジョニング型(Amazon RDSなど)は、起動しているインスタンスに対して時間単位で課金されるため、消費パターンが予測でき、リザーブドインスタンス (長期割引プラン) を購入することでランニングコストを大幅に削減できます。
選定基準3 | 求められる可用性と移行のしやすさで最終決定する
データ構造とワークロード特性を整理したら、最後は可用性の要件と既存システムからの移行のしやすさを考慮して最終決定します。
▼可用性の要件で選ぶ
| 求める可用性のレベル | 向いているサービス | 理由 |
|---|---|---|
| 極めて高い (ミッションクリティカルな要件) | Amazon Aurora (マルチAZ構成) | 複数AZへの自動レプリケーションと高速なフェイルオーバーを実現 |
| 標準的 (一般的な本番環境レベル) | Amazon RDS (マルチAZ構成) | マルチAZ配置でフェイルオーバーに対応し、AuroraよりコストをおさえてRDB運用が可能 |
| コスト重視 | Amazon RDS (シングルAZ構成) | 開発・検証環境や小規模システムでのコスト最小化に向いている |
金融・医療・基幹業務などのミッションクリティカルなシステムでは、Amazon Auroraの (マルチAZ構成) を選択する傾向があります。一方、コスト重視の中小規模システムや、サービス停止が許容できる内部向けシステムにはAmazon RDS (シングルAZ構成) が向いています。
オンプレミスや既存クラウドからの移行を検討している場合、DBエンジンの互換性が重要なポイントです。
▼移行のしやすさで選ぶ
| MySQL・PostgreSQLからの移行 | Amazon AuroraはMySQL・PostgreSQLと完全互換のため、移行コードの変更を最小限に抑えられる |
|---|---|
| Oracle・SQL Serverからの移行 | Amazon RDSがOracle・SQL Serverエンジンに対応しており、オンプレミス環境の設定をある程度引き継げる |
| MongoDBからの移行 | Amazon DocumentDBがMongoDB APIと互換性があり、既存のドライバー・ツールをある程度利用できる |
オンプレミスや既存クラウドからの移行は、AWS Database Migration Serviceを活用することで、移行中も元のデータベースを稼働させ続けながらデータ移行できるため、サービス停止時間を最小化することが可能です。また、Amazon AuroraはAmazon RDSと比較してインスタンスコストが高くなる傾向があります。
しかし、MySQLやPostgreSQLと比較して高い処理能力を持つため、同等のパフォーマンスを実現するために必要なインスタンス数が少なくなり、トータルコストは安くなるケースもあります。インスタンス単価だけでなく、インスタンス台数・運用工数・ライセンス費用を含めたTCOで比較することも大切です。
AWSデータベース活用におけるユースケース

AWSのデータベースサービスは、用途に合わせて適切なサービスを選ぶことで、システムの品質・コスト・運用効率を大きく向上させられます。
ここでは、現場で特に多く採用される4つのユースケースを取り上げ、どのサービスをどのように組み合わせて活用するのかを具体的に解説します。
基幹システム・既存データベースのクラウド移行 (Amazon RDS・Amazon Aurora)
オンプレミスで稼働しているOracleやSQL Serverなどのレガシーなシステムをクラウドへ移行したい場合、AWS Database Migration ServiceとAmazon RDS・Amazon Auroraの組み合わせが一般的なアプローチです。
AWS Database Migration Serviceは、移行中のサービス停止時間のリスクを2段階方式で解消します。
| フルロード | 移行元DBに蓄積された既存のデータをAWS上のターゲットDBへ一括コピーする |
|---|---|
| CDC (Change Data Capture) | フルロード中に発生した追加・更新・削除の差分を継続的にレプリケーションし、移行元と移行先のデータを同期し続ける |
この方式により、対象のデータベースを稼働したまま移行を実現します。最終的なデータ同期の遅延が十分に小さくなったタイミングでアプリケーションの書き込みを一時停止し、移行先に切り替えるため、実際のサービス停止時間を少なく抑えられます。
移行後はバックアップ・パッチ適用・フェイルオーバーをAWSが代行するため、移行前と比べて運用工数を大幅に削減できます。異なるエンジン間の移行 (例:OracleからAmazon AuroraのPostgreSQL) には、AWS SCT (Schema Conversion Tool) でスキーマ変換の難易度を事前に評価するのが効果的です。
大規模アクセスに耐えるWeb・モバイルアプリ基盤(Amazon ElastiCache・Amazon DynamoDB・Amazon Aurora Serverless)
ECサイトのセールやゲームの新機能リリースなど、トラフィックの急増が予測しにくいシステムには、Amazon ElastiCache・Amazon DynamoDB・Amazon Aurora Serverlessの組み合わせが向いています。
▼サービスの役割
| Amazon ElastiCache | セッション情報 (一時データ) の取り扱い |
|---|---|
| Amazon DynamoDB | 大量データ・ログ・ユーザーの活動履歴などの取り扱い |
| Amazon Aurora Serverless | 決済・在庫など厳密なトランザクション処理 |
各サービスの詳細な説明は「AWS DBの種類一覧」をご確認ください。
社内に蓄積されたデータの有効活用・高速分析 (Amazon Redshift・Amazon Athena)
複数システムに散在するデータを集約・分析してKPI管理や経営判断に活かしたい場合は、Amazon RedshiftとAmazon Athenaを目的に応じて使い分けます。
▼主な使い分け
| Amazon Redshift | 定常的な大規模集計・BIダッシュボード |
|---|---|
| Amazon Athena | スポットなアドホック (探索的) 分析・ログ調査 |
生成AIを活用した社内ナレッジ検索 (Amazon OpenSearch Service)
社内ドキュメントや議事録・マニュアルをAIで横断検索する仕組みとして、Amazon OpenSearch ServiceとAmazon BedrockによるRAG (検索拡張生成) 構成が利用されています。
この構成は、生成AIを活用した社内ナレッジ検索や社内データ活用の基盤として注目されています。
| Amazon OpenSearch Service | ・社内ドキュメント (PDF・議事録・マニュアルなど) をAmazon Bedrockと連携して数値化(ベクトル化)し、保管する ・利用者の質問に関連するドキュメントを高速検索 |
|---|---|
| Amazon Bedrock | ・Amazon OpenSearchから取得した関連情報をコンテキスト (前提知識) として、社内データに基づいた回答を生成する |
この構成により、従来のキーワード検索では見つからなかった意味的に関連する情報を横断的に検索・回答するシステムを実現できます。
Amazon OpenSearch ServiceはAmazon Bedrockとの連携における有力なベクトルDB選択肢の一つであり、キーワード検索とベクトル検索を組み合わせたハイブリッド検索による高い検索精度が特長です。
AWS データベースの料金体系

AWSのデータベースサービスは従量課金を基本としており、利用した分だけ支払う仕組みになっています。しかし、課金の要素は複数にわたるため、全体像を正しく理解しておかないと、想定以上のコストが発生することもあります。
ここでは、AWSのデータベースサービスに共通する料金構造を、基本コスト・利用形態による割引・サーバーレスモデルの従量課金・導入後のコスト最適化の4つの観点から解説します。
料金の柱、3つの基本コスト
AWSが提供するマネージドサービスのデータベースは、大きく3つの料金体系で構成されています。
| インスタンス費用 | ・データベースの起動時間に対してコストが発生する ・インスタンスの性能が高いほどコストも上がる ・選択するDBエンジンや利用するリージョンによって単価が変動する ※ マルチAZ構成は、スタンバイ側の分も課金されるため費用が高くなるため注意が必要です。 |
|---|---|
| ストレージ費用 | ・データベースのデータ容量と、バックアップ容量に対してGB単位でコストが発生する ・高い処理性能 (I/O性能) を持つストレージを選ぶほど単価が上がる ・自動バックアップは、利用中のデータベースの合計ストレージ容量と同じ分までは無料で保存でき、超過分のみ課金される |
| データ転送費用 | ・データベースへのデータ受信は無料だが外部へのデータ送信には課金が発生する ・同一AZ内にあるEC2とデータベースの通信などは原則無料となる ※ AZをまたぐ通信や、別リージョンへの通信には転送コストがかかるため注意が必要です。 |
これら3つのコスト要素を意識してサービスを設計することが、予算超過を防ぐために重要です。
利用形態による割引 (リザーブドインスタンス・Database Savings Plans)
AWSのデータベースサービスにおける基本の課金方式は、使った分だけを支払うオンデマンドです。オンデマンドは、DBインスタンスが起動している時間に対して時間単位で課金されます。
▼オンデマンドの主なポイント
| ・初期費用や長期契約が不要 ・いつでも開始・停止できる柔軟性ある ・長期間にわたって常時稼働する本番環境では割高になる傾向がある |
本番環境のように長期間にわたって常時稼働するシステムでオンデマンドを利用し続けると、コストが割高になる可能性があります。AWSでは、長期利用を前提とした割引モデルのリザーブドインスタンスとDatabase Savings Plansを用意しています。
リザーブドインスタンス
リザーブドインスタンスは、1年または3年の利用を前提に予約購入することで、オンデマンドと比較してコストを削減する仕組みです。支払い方法は全額前払い・一部前払い・前払いなしの3種類があり、前払い額が大きいほど割引率が高くなります。
▼リザーブドインスタンスの主なポイント
| ・オンデマンドと比較してコスト削減が可能 ・MySQL・PostgreSQL・Aurora・Oracleなど主要なDBエンジンに対応 ・一部エンジンを除き同一インスタンスファミリー内であればサイズの柔軟な変更が可能・購入後のキャンセルは不可のため、事前のサイジング評価が重要となる |
リザーブドインスタンスは、本番環境のデータベースなど、長期間にわたって構成や稼働状況が変動しない安定したシステムでの利用に向いています。
Database Savings Plans
Database Savings Plansは、1年間にわたり一定の使用量を契約することで、対象のデータベースサービスに対してコストの削減を可能にする仕組みです。リザーブドインスタンスと異なり、DBエンジン・インスタンスファミリー・リージョンをまたいで割引が自動適用される特長があります。
▼Database Savings Plansの主なポイント
| ・前払い不要で1年間の使用量をコミットする方式 ・Amazon Aurora・Amazon RDS・Amazon DynamoDBなど幅広いサービスに対応 ・サーバーレスの利用にも割引が適用される ・プロビジョニング型インスタンスには割引が適用される・インスタンスの移行や構成変更を行っても割引が継続するため、モダナイゼーションを進めやすい |
リザーブドインスタンスとDatabase Savings Plansは同一ワークロードに対して併用できません。新規に割引を検討する場合は、利用するサービスの変更可能性も考慮したうえでどちらを選択するか判断することが大切です。
サーバーレスモデルにおける従量課金の経済性
AWSのデータベースサービスの中には、サーバーレスモデルを採用することで、インスタンスの管理や容量のプロビジョニングが不要になるサービスがあります。サーバーレスモデルのメリットは、リソースの実利用量に応じた課金が基本となり、アイドル時間のコストを大幅に抑えられる点にあります。
代表的なサーバーレス対応サービスと、それぞれの課金の仕組みは以下の通りです。
| Amazon Aurora Serverless | ・ワークロードに応じてAurora Capacity Unit (ACU) が自動でスケールし、使用したACU時間に対して秒単位で課金が発生する ・最小ACUをゼロに設定した場合、リクエストがない期間はACU課金が発生しない |
|---|---|
| Amazon DynamoDB (オンデマンドモード) | ・読み取り・書き込みリクエストの回数に対して従量課金される ・プロビジョニングモードのようにキャパシティを事前に確保する必要がなく、アイドル時のコストはストレージ料金のみとなる |
| Amazon Athena | ・S3上のデータに対してクエリを実行した際に、スキャンしたデータ量に応じて課金される ・Parquet形式やORC形式などの列指向フォーマットに変換し、パーティションを適切に設定することで、スキャン量を削減でき、コスト最適化につながる |
サーバーレスモデルは、トラフィックが不規則な開発・検証環境、アクセス量の予測が難しいスタートアップ、定期レポートの生成やスポット的なログ分析といったケースで特に経済的です。ただし、コールドスタート (一定時間のアイドル後に再起動される際の遅延) が発生する場合がある点は考慮が必要です。
常時高負荷のシステムでは、プロビジョニング型の方がコストパフォーマンスに優れるケースもあるため、ワークロードの特性に応じた選択が重要になります。
導入後に実践すべきコスト最適化3つのポイント
AWSのデータベースサービスは導入した後も、継続的にコストを見直すことで削減効果が得られる可能性があります。
見直しの観点は以下の通りです。
| リザーブドインスタンスまたはDatabase Savings Plansの活用 | 本番環境の安定稼働DBは、長期利用の割引を適用してココスト削減を検討する |
|---|---|
| 不要リソースの停止・削除 | 開発・テスト用データベースは業務時間外に停止スケジュールを組み、スナップショットで管理することでコスト削減を検討する |
| ストレージとI/Oの最適化 | RDSのgp2からgp3への移行や、AthenaのデータフォーマットをParquetへ変換するなどで、ストレージ費用とI/O費用の最適化を検討する |
3つのポイントを定期的に見直し、システムの稼働状況に合わせたチューニングを続けることが、AWSの費用対効果を出すポイントです。
AWS データベース導入時の注意点

マネージドサービスのデータベースはインフラ管理の負担を大幅に軽減します。しかし、導入前に把握しておくべき注意点があります。
ここでは、データベースの導入における設計・セキュリティ・移行・互換性の4点を整理します。
管理者が担うべき役割の変化 (マネージド≠保守不要)
マネージドサービスのデータベースを導入すると、OSのパッチ適用・バックアップ・フェイルオーバーはAWSが担当します。
一方、以下の領域は引き続き利用者側の責任です。
| 作業領域 | 主な作業内容 |
|---|---|
| データ設計・スキーマ管理 | テーブル構造・正規化・インデックス設計 |
| クエリチューニング | スロークエリの特定、実行計画の最適化 |
| パラメータグループ管理 | DBエンジン設定のカスタマイズ・適用 |
| アクセス権限管理 | DBユーザーの作成・ロール付与・最小権限運用 |
AWSは「ユーザーはクエリチューニングに責任がある」としています。クエリのパフォーマンスはデータ設計・データ量・アプリのワークロードに大きく依存するため、データベースの負荷状況・上位SQLの把握・実行計画の確認といった監視観点を押さえ、問題となるクエリを継続的に特定・改善する運用体制を整えることが大切です。
マネージドサービスのデータベース導入後は、担当者の役割がインフラ保守からアーキテクチャ設計・パフォーマンス最適化へとシフトする点で注意が必要です。
ネットワークとセキュリティ設計の重要性
データベースはシステムの中でも特に機密性の高いコンポーネントです。AWS公式が推奨する多層防御の設計を導入時から適切に行うことが必要です。
▼セキュリティ設計の3つの柱
| ネットワーク分離 | ・データベースは必ずVPC内のプライベートサブネットに配置し、パブリックアクセスは無効化する ・セキュリティグループで接続元IPアドレスとポート番号を最小権限で制御する |
|---|---|
| IAM+KMSによる多層防御 | ・IAMポリシーでRDSリソースの操作権限を持つユーザーを限定し、AWS KMSでDBストレージとスナップショットをAES-256で暗号化する |
| 通信経路の保護 | ・アプリケーションとデータベースの通信はSSL/TLSで必ず暗号化する ・AWS内部のサービス間通信はVPCエンドポイントを活用しインターネットを経由させない |
導入後はAWS Security Hub CSPMでセキュリティ設定がベストプラクティスに沿っているか定期的に評価することが必要です。
移行におけるサービス停止時間とデータ整合性の確保
既存データベースをAWSへ移行する際は、サービス停止時間とデータ整合性の確保が最大の課題です。AWS Database Migration ServiceのCDC方式(フルロード+差分同期)を用いると、切り替え時のダウンタイムを最小化できます。
移行時に注意すべき3つのポイントは次のとおりです。
| レプリケーションインスタンスのサイズ選定 | ・サイズが不足すると移行速度の低下やラグ蓄積が起きる ・本番移行前に十分な負荷テストを実施し、適切なインスタンスクラスを選定する |
|---|---|
| データ検証の実施 | ・AWS Database Migration Service内蔵のデータ検証機能を有効化し、移行元・移行先のレコード数や内容の一致をシステム的に確認する |
| 段階的な切り替え | ・CDCの差分 (レイテンシ) が十分に小さくなったタイミングで切り替えを行い、切り替え後もしばらく旧環境を維持してロールバックに備える |
AWS Database Migration Serviceによる自動化と慎重な移行計画を組み合わせることで、ダウンタイムとデータ欠損のリスクを排除できます。
最新機能のリージョン制限と互換性
AWSは新サービスを段階的にリリースするため、最新機能ほどリージョン対応が限定される傾向があります。また、PostgreSQL互換・MySQL互換をうたうサービスでも、完全な互換性が保証されているわけではありません。
Amazon Aurora DSQLは2024年のre:Invent 2024で発表されました。しかし、PostgreSQL互換とはいえ、未対応な機能があります。主な未対応機能は以下となっており、既存アプリからの移行前に十分な互換性検証が必要です。
| ・外部キー制約 ・ストアドプロシージャ (PL / pgSQL) やトリガー ・一時テーブル ・1つのトランザクション内でのDDLとDMLの混在 |
Amazon Aurora DSQLはPostgreSQLのRepeatable Readに固定されたトランザクション分離レベルで動作し、Serializable分離レベルは選択できません。未対応機能の最新状況は、AWS公式ドキュメントを確認してください。
また、Amazon Aurora DSQLに限らず、各DBエンジンのメジャーバージョンアップに伴う非互換変更も定期的に発生します。AWSのリリースノートを継続的に追跡し、計画的なアップグレードを行う運用体制を整えることが重要です。
まとめ
本記事では、AWSにおけるデータベースサービスの全体像から選定方法・ユースケース・料金体系・導入時の注意点まで幅広く解説しました。AWSのデータベースサービスは、インフラ運用を効率化し、ビジネスに最適なデータベースを柔軟に選択できるのが強みです。ただし、クエリの最適化やセキュリティ設定といった中身の運用は利用者が行う必要があります。
まずは小規模な検証 (PoC) を通じて、挙動やコストを正しく把握した上で、段階的な導入を検討してください。
AWSにおけるデータベースの導入なら、国内25,000人以上(※1)の技術者を擁し、大手企業を中心に2,555社との取引実績(※2)を持つ株式会社テクノプロにお任せください。設計から運用、コスト最適化まで、一括して任せることができます。
※1:2024年6月末時点
※2:(株)テクノプロ及び(株)テクノプロ・コンストラクション 2024年6月末時点
監修者

テクノプロ・ホールディングス株式会社
チーフマネージャー
中島 健治
2001年入社
ITエンジニアとして25年のキャリアを持ち、チーフマネージャーとしてテクノプロ・エンジニアリング社にて金融・商社・製造業など多業界でのインフラ基盤構築に従事してきた。2008年から2024年まで、オンプレミス環境でのストレージ・サーバ統合基盤の設計・構築を手掛け、特に生成AI・データ利活用分野のソリューション開発実績が評価されている。現在は技術知見を活かしたマーケティング戦略を推進している。






