監修者

テクノプロ・ホールディングス株式会社
チーフマネージャー
中島 健治
2001年入社
ITエンジニアとして25年のキャリアを持ち、チーフマネージャーとしてテクノプロ・エンジニアリング社にて金融・商社・製造業など多業界でのインフラ基盤構築に従事してきた。2008年から2024年まで、オンプレミス環境でのストレージ・サーバ統合基盤の設計・構築を手掛け、特に生成AI・データ利活用分野のソリューション開発実績が評価されている。現在は技術知見を活かしたマーケティング戦略を推進している。
AWSのログ監視は、安定稼働やセキュリティ確保に欠かせませんが、設計次第でログ肥大化や障害調査の遅れ、コスト増大を招きます。
本記事では、CloudWatch Logsを中心に、目的に応じたログ監視の設計方法から分析・コスト削減、SaaSツールとの使い分けまでをわかりやすく解説します。
AWSのログ監視なら、世界規模の製造メーカーや大手IT企業など多種多様なシステム構築を支援してきた株式会社テクノプロにご相談ください。ITシステム構築に強みを持つ株式会社テクノプロなら、AWS導入の準備段階からビジネス設計、本稼働、運用の各段階に応じて、経験豊富なエンジニアが効率的に支援を行い、費用対効果の高いサービスを実現します。
AWSログ監視が評価される理由

本章では、AWSログ監視が評価される理由を、目的と設計の観点から整理します。
障害対応・セキュリティ監査・コスト最適化を同時に満たせるため
ログ監視は、目的を明確にして設計することが大切です。一般的に、ログ監視では障害対応・セキュリティ監査・コスト最適化が主要な目的といえます。
3つの目的を整理すると次のようになります。
| 障害対応 | ・メモリ不足やタイムアウトなどのアプリケーションエラーログをリアルタイムで監視し、重大な障害への発展を未然に防ぐ ・サービスの異常や予兆を迅速に検知し、機会損失を最小限に抑える ・障害発生時の原因特定をスムーズにし、復旧時間を短縮する |
| セキュリティ監査 | ・コンプライアンス要件に対応し、監査に必要な証跡 (ログ) を確実に保全する ・「いつ・誰が・どのデータ」にアクセスしたかを追跡できる状態にする ・不正な操作や権限昇格などのセキュリティインシデントを即座に発見する |
| コスト最適化 | ・リソースの使用状況を分析して過剰な割り当てや無駄な稼働を特定する ・すべてのログを保存するのではなく、価値のあるデータを選別して保管コストを抑える ・ログの保存期間や格納先 ( ストレージ) を管理し、コストの肥大化を防止する |
これら3つの目的をバランスよく設計することが、安定した運用を実現する観点から重要です。どれか一つでも欠ければ、運用負荷の増大や重大なセキュリティリスクを招く可能性があります。
AWS環境では、これら3つの目的を前提としたログ監視の仕組みが統合的に整備されており、運用や監査の現場から高く評価されています。
障害対応では、システムの異常を自動で検知して通知する仕組みにより、復旧時間の短縮が可能です。セキュリティ監査では、操作履歴やアクセス状況を継続的に記録し、監査証跡を保存できます。コスト最適化の面でも、不要なログの除外や保存期間の自動管理によって、運用コストを抑える設計ができます。
運用負荷や見落としを防ぐ仕組みまで含めて設計できるため
組織がログ監視の導入をしても、設計や運用の不備によりトラブルに陥るケースがあります。これらは、運用担当者を疲弊させるだけでなく、重大な障害の見落としや復旧の遅れにつながる場合があります。トラブルを防止するためには、設計段階から対策を行うことが必要です。
ログ監視の失敗には、主に「アラート疲れ」と「ログのサイロ化」という典型的なパターンが存在します。それぞれの状態・リスク・対策は次の通りです。
▼アラート疲れ:重要度の低い通知が頻発し、担当者が疲弊する
| リスク | 本当に重要な警告を見逃す可能性がある |
| 対策 | 重要な事象のみ通知し、軽微なものはレポート化する |
▼ログのサイロ化:ログがサービスやサーバーごとに分散して保存されている状態
| リスク | 複合的な障害の際、原因特定のための調査に時間がかかる |
| 対策 | ログを一元管理して横断的な検索を可能にする |
ログ監視の設計は、すべてのログを監視・通知することが正解ではありません。
設計段階でリスクを予測して対策を検討することがポイントです。
AWS環境では、これらの課題に対しても有効な対策が用意されています。
アラート疲れには、アラートの重要度を柔軟に制御できる仕組みがあり、担当者の負担を軽減できます。また、複数のリソースやアカウントから出力されるログを一元的に集約・分析できる仕組みを活用することでログのサイロ化の解消が可能です。
このように、運用負荷や見落としを防ぐ仕組みまで含めて設計できる点が、AWSログ監視が評価されている理由の一つです。
AWSログ監視の中核「CloudWatch Logs」とは?役割と特徴

AWS環境におけるログ監視を実現するうえで、中心的な役割を果たすのがCloudWatch Logsです。このサービスは、AWSの各リソースやオンプレミスサーバーからログを収集し、一元管理できるフルマネージドのログ基盤として機能します。
この章では、CloudWatch Logsの役割と、主要機能・データ構造・ログ収集方式について整理します。
CloudWatch Logsの主な機能 |モニタリング・分析・アーカイブ
CloudWatch Logsは、AWSにおけるログ監視の中心となるサービスです。ログの保存だけでなく、モニタリング(監視)・分析・アーカイブ(長期保存)といった運用に必要な機能を備えています。
各機能の特徴は以下の通りです。
| モニタリング | ・ログデータをリアルタイムに監視し、異常検知時にアラートを出す ・ログの検知はメトリクスフィルターを使用する ・ログ内の「ERROR」などの文字列をカウントし、閾値を超えた場合に管理者へ通知する |
| 分析 | ・蓄積されたログデータを、高速に検索・集計する ・分析には「CloudWatch Logs Insights」を利用し、専用クエリで条件抽出や時間ごとの発生傾向を可視化する ・専用のクエリ言語 (問い合わせ用の言語) を用いて、条件に合うログの抽出や、時間ごとの発生頻度を分析する |
| アーカイブ (長期保存) | ・監査やコンプライアンス対応など、長期保管が求められるケースでも柔軟に対応できる ・古いログデータをCloudWatch Logsのエクスポート機能を使ってS3に保存し、長期保管を実現するS3のライフサイクルルールを活用して、古いログをGlacierなどへ移行し、コストを最適化する |
これら3つの機能を組み合わせることで、異常検知から原因分析、ログ保存というログデータのライフサイクルを一貫して管理できます。
ログデータを整理する構成要素|「ロググループ」と「ログストリーム」
CloudWatch Logsのデータ階層構造は、ロググループとログストリームという2つの要素で構成されています。
これらはファイルシステムにおけるフォルダ (ロググループ) とファイル (ログストリーム) の関係に似ていますが、AWS独自の管理ルールがあるため、正しく理解する必要があります。
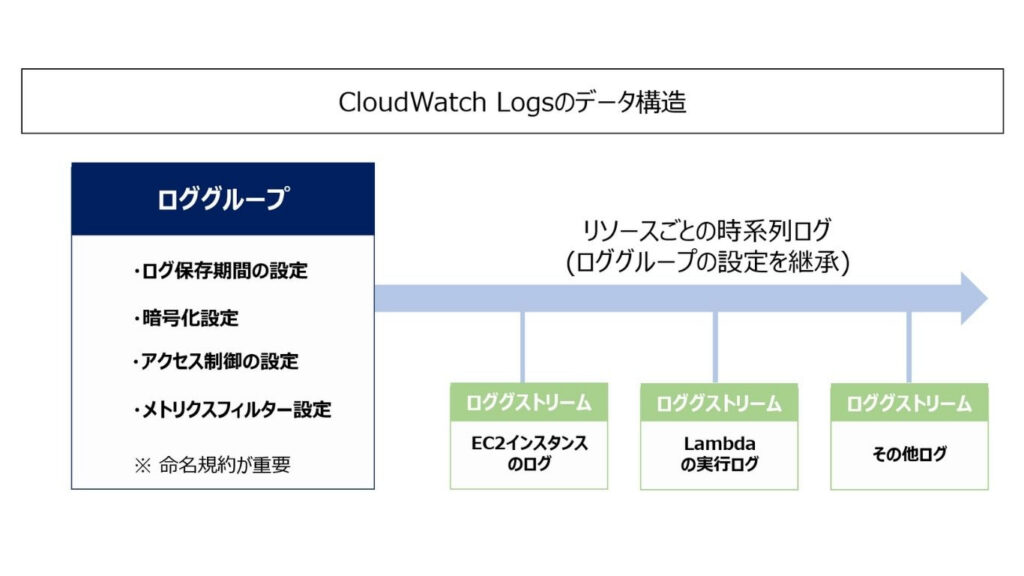
ロググループとログストリームの役割の違いは次の通りです。
| 役割と特徴 | 設定可能な項目 | |
| ロググループ | 【役割】 ログ管理やポリシー (ルール) 適用のための単位 【特徴】 ログを格納する大きな入れ物 (同じ保存期間やアクセス権限でログをひとまとめ) | ・ログの保存期間 ・暗号化設定 ・アクセス制御 ・メトリクスフィルター |
| ログストリーム | 【役割】 各リソース (EC2・Lambdaなど) から出力されるログを時系列で記録する単位 【特徴】 ロググループ内に複数存在し、リソースや実行ごとに1ストリーム作成される例: EC2インスタンス単位・Lambda実行環境単位 | なし (設定は親であるロググループに従う) |
ロググループは、保存期間やアクセス権限の管理単位です。命名規則によって管理や分析効率が大きく変わるため、ルール設計は慎重に行う必要があります。
2つのログ収集経路|「CloudWatch Agent」と「Vended Logs」の違い
CloudWatch Logsへログを送る方法は、大きく「CloudWatch Agent」と「Vended Logs」の2種類に分かれます。前者はユーザーが管理するサーバー(EC2やオンプレミス)からログを送信する方式で、後者はAWSのマネージドサービスから自動でログを送信する方式です。
CloudWatch AgentとVended Logsの特徴は以下の通りです。
| CloudWatch Agent | Vended Logs | |
| 監視対象 | EC2インスタンス・オンプレミスサーバー | AWSマネージドサービス (CloudTrail・VPC Flow Logs・Lambda等) |
| 仕組み | サーバーOS内にソフトウェア (Agent) をインストールし、内部のログファイルを読み取ってCloudWatch Logsへ転送する | サービスに標準搭載されたログ機能であり、ログ送信の設定を有効化することで、対象サービスからCloudWatch Logsへ自動送信する |
| 取得ログ | OSログやアプリログ (Apache・Java等) | 各サービスの動作ログやアクセスログ |
| 特徴 | メモリ使用率などのカスタムメトリクスも同時に収集可能 | サーバーへのログインやAgent導入が不要で、即座に利用可能 |
| 注意点 | ユーザー自身でAgentのインストールと設定が必要 | ログ量が膨大になる場合があるため (VPC Flow Logs等) 、対象範囲に絞ったコスト管理が必要 |
2つの経路で収集されたログは、最終的にCloudWatch Logsで一元的に管理できます。オンプレミスのOSログからLambdaの実行ログ、VPC通信ログまでを同じ画面で横断検索できるため、運用効率が大幅に向上します。
※厳密にはVended Logsは特定のインフラログを指します。しかし、本記事では収集方法 (エージェントの有無) で分類しやすくするために、AWSサービス標準のログを含めて整理しています。
AWSログ監視における最小構成の構築手順

AWSログ監視は高機能な反面、設計や導入の進め方によっては構築や運用が複雑になりがちです。
そこで本章では、EC2上のアプリログをCloudWatch Logsで監視し、エラーを検知してメールやSlackで通知する最小構成の構築手順を解説します。多くのシステム監視において基本となるパターンであり、理解することで他のリソースへの応用も容易になります。
ステップ1 : IAMロールの作成(CloudWatchAgentServerPolicy)
EC2インスタンスがCloudWatch Logsにログを書き込むためには、IAMで適切な権限設定が必要です。AWSのセキュリティ原則に従い、アクセスキーをサーバー内に埋め込むのではなく、IAMロールを使用して権限付与を行います。
ログ転送は、主に以下の権限が必要です。
| logs | ・PutLogEvents (ログの書き込み) ・CreateLogStream (ログストリームの作成) |
| cloudwatch | ・PutMetricData (メトリクスの送信) |
これらの権限は、AWSが提供する管理ポリシー「CloudWatchAgentServerPolicy」にあらかじめ定義されています。既存のポリシーを利用することで、複雑な記述をせずに設定が可能です。
CloudWatchAgentServerPolicyを含むIAMロールを作成し、EC2に適用する手順は以下の通りです。
| 1.AWS管理コンソールのIAM画面を開き、「ロールを作成」をクリックする 2.信頼されたエンティティとして「AWSのサービス」を選び、ユースケースで「EC2」を選択する 3.許可ポリシーの検索画面で、以下の2つのポリシーを検索し、チェックを入れる ・CloudWatchAgentServerPolicy (ログ転送用) ・AmazonSSMManagedInstanceCore (SSM接続用) 4.任意のロール名 (CloudWatchAgentRole等) を入力し、ロールを作成する 5.EC2コンソールで対象インスタンスを選び、「アクション → セキュリティ → IAMロールを変更」から作成したロールを割り当てる ※上記操作で、IAMロールがインスタンスプロファイルとしてEC2に関連付けられる |
以上の手順により、インスタンスは認証情報を保持することなく、安全にCloudWatch Logsへのアクセスが可能になります。
ステップ2 : CloudWatch Agentの設定
CloudWatch Agentは、ログファイルを読み取り、CloudWatch Logsへ転送する役割を担うコンポーネントです。
まずはEC2インスタンス内でCloudWatch Agentをセットアップします。Agentの設定ファイル (amazon-cloudwatch-agent.json) を作成しましょう。
設定ファイルには以下を定義します。
| a: 収集対象のログファイルパス b: 転送先のロググループ名 c: ログストリーム名 |
設定ファイルは通常JSON形式で記述され、logs セクションと metrics セクションに分かれます。ログ収集の場合、logs セクション内の collect_list 配下に設定を記述します。
以下は、/var/log/app/error.log を収集し、/aws/ec2/app-logs というロググループに転送する設定例です。
| ■設定ファイルの記載例 (JSON) { “logs”: { “logs_collected”: { “files”: { “collect_list”: [ { “file_path”: “/var/log/app/error.log”,…a “log_group_name”: “/aws/ec2/app-logs”,…b “log_stream_name”: “{instance_id}”…c } ] } } } } |
「c」は、「instance_id」というプレースホルダーを使用することで、自動的にインスタンスIDが名前に適用され、どのサーバーのログかを識別できるようになります。
設定ファイルは、SSMパラメータストア (設定情報の一元管理) に保存し、Agentへ適用することが一般的な手順です。設定ファイルを個々のサーバーに直接配置するのではなく、AWS Systems Managerのパラメータストアに保存することで、複数台のサーバーに対して一元的に設定を配布・適用することが可能です。
最後に、EC2インスタンス内で以下のコマンドを実行し、SSMから設定を読み込んでAgentを起動して完了となります。
| ■コマンド例 sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c ssm:AmazonCloudWatch-Config -s ※ 「-c ssm:AmazonCloudWatch-Config」は、SSMパラメータストアに保存したパラメータ名を指定します。 |
ステップ3 : メトリクスフィルターの作成 (特定エラー文字列の監視)
ログの収集ができたら、次は監視設定です。収集したログから、特定の文字列 (ERROR・FATAL等) をリアルタイムで検知する方法を設定します。
CloudWatch Logsコンソールで対象ロググループに対し、メトリクスフィルターを作成する手順は以下の通りです。
| 1.CloudWatchコンソールの「ロググループ」から対象のグループを選択する。 2.「メトリクスフィルター」タブをクリックし、「メトリクスフィルターを作成」を選択する。 3.フィルターパターンを定義する。 例: ログ内の「ERROR」という文字を検知したい場合は、テキストボックスに「ERROR」と入力する。 4.以下の項目を入力してメトリクスの割り当てを行う。 ・フィルター名 ・メトリクス名前空間 (例: MyApp/Errors) ・メトリクス名 (例: ApplicationErrorCount) ・メトリクス値 (通常は1) |
以上により「ログにERRORという文字が1行出るたびに、メトリクスに1を加算する」という処理が自動的に行われます。
ステップ4 : SNSトピックとCloudWatchアラームによる通知(メール・Slack)
最後のステップとして、検知したエラーを管理者に通知する仕組みを作ります。ステップ3で作成したカスタムメトリクスに基づいてアラートを発報する設定です。
通知設定は、以下の流れで行います。
| ・通知先 (SNS) の作成とメール設定Chatbot ・Slack通知の設定 (Chatbotの利用) ・CloudWatchアラームの作成 |
通知先 (SNS) の作成とメール設定
通知の受け皿となるSNS (AWSの通知配信サービス) トピック (通知をまとめて配信する単位) を次の手順で作成し、その後メールアドレスを登録します。
| 1.SNSのコンソールで「トピック」を作成する (例: SystemAlertTopic) 。 ※トピックタイプは「スタンダード」を選択する 2.作成したトピックに対し「サブスクリプション」を作成する 3.プロトコルに「Email」を選択し、通知先のメールアドレスを入力する 4.入力したアドレスに届く確認メールのリンクをクリックして承認し、準備を完了する |
Slack通知の設定 (Chatbotの利用)
Slackへ通知を行う場合は、ChatbotやLambdaを経由して、SNSのメッセージをSlackに転送します。
一般的にはChatbotを利用する方法がベストプラクティスです。コードを書く必要がなく導入が容易で、通知内容も自動で見やすく整形されるためです。
| 1.Chatbotコンソールで「チャットクライアント」としてSlackを設定し、ワークスペースへのアクセスを許可する 2.チャット設定で、先ほど作成したSNSトピックを紐付ける |
これにより、SNSへの通知が自動的にSlackチャンネルへ転送されるようになります。Slackへの通知は、メールよりもリアルタイム性が高く、見逃しを防げます。
CloudWatchアラームの作成
最後に、メトリクスと通知先を紐付けてアラームを完成させます。
| 1.CloudWatchコンソールの「アラーム」から、ステップ3で作成したメトリクスを選択する。 2.条件を「5分間の合計が1以上」に設定する。 3.アクション設定で、作成したSNSトピックへの通知を指定してアラームを作成する。 ※「欠測データの処理」で「適正 (notBreaching)」を選択する。 |
これで全ての構築は完了です。 エラーログが出力されると、メトリクスがカウントされ、アラーム状態となり、メールやSlackに通知が届くようになります。
AWSのログ監視なら、世界規模の製造メーカーや大手IT企業など多種多様なシステム構築を支援してきた株式会社テクノプロにご相談ください。ITシステム構築に強みを持つ株式会社テクノプロなら、AWS導入の準備段階からビジネス設計、本稼働、運用の各段階に応じて、経験豊富なエンジニアが効率的に支援を行い、費用対効果の高いサービスを実現します。
CloudWatch Logs Insightsによるログ分析の活用例と効果

AWSでは「CloudWatch Logs Insights」という対話的なログ分析機能が提供されています。ここでは、CloudWatch Logs Insightsの具体的な活用シナリオ3例を紹介し、ログ分析がもたらす効果を解説します。
活用シナリオ1:障害の迅速な検知と復旧(サービス信頼性の向上)
大量のログから障害の兆候や原因を素早く特定できれば、サービスの復旧を早めることが可能です。CloudWatch Logs Insightsの活用で、ログ確認作業を効率化し、「どのサーバーの・どの機能が・何が原因で停止したか」をすぐに特定できます。
具体的には、以下の分析ができます。
| サーバー横断の一括検索 | ・複数台のサーバーやロググループをまとめて検索できる ・「どのサーバーでエラーが出ているか」をすぐに特定が可能となる |
| エラー原因の即時特定 | ・膨大なログの中から、「ERROR」などのキーワードで停止した機能や問題箇所だけを抽出できる ・発生時刻順に並べることで、「デプロイ直後からエラーが増えた」といった障害のきっかけ (因果関係) を素早く把握できる |
CloudWatch Logs Insightsを活用することで、トラブルシューティングを迅速化し、復旧時間 (MTTR) を最小限に抑えることができます。
活用シナリオ2:セキュリティとコンプライアンス監査の効率化
「誰が機密データにアクセスしたか」「不正な操作が行われていないか」といった監査証跡を、高速に検索・追跡できることも大きなメリットです。CloudWatch Logs Insightsを活用することで、膨大なログからリスクのある操作をすぐに特定できます。
具体的には、以下の分析ができます。
| 不正アクセスの追跡 | ・特定のIPアドレスからのアクセスや不正な操作をすぐに抽出できる ・「誰が機密データにアクセスしたか」をすぐに特定が可能となる |
| 監査レポートの効率化 | ・管理者権限の付与といった重要イベントを抽出するクエリを保存できる ・スケジュールされたクエリ機能を使えば、定期的な監査レポート作成を自動化できる |
CloudWatch Logs Insightsによる監査の効率化は、監査対応コストの削減につながります。
活用シナリオ3:ボトルネックの特定(レイテンシー改善)
CloudWatch Logs Insightsを活用することで、処理時間の数値を集計し、ボトルネックをランキング形式で可視化できます。「Webサイトの表示が遅い」というクレームに対し、膨大なログから遅延の原因となっている箇所の特定が可能です。
具体的には、以下の分析ができます。
| 遅延しているAPIの特定 | ・アプリログを集計し、平均レスポンスタイムが遅いAPIのエンドポイントを特定できる ・「どの処理に時間がかかっているか」を確認できる |
| データベースや通信の遅延検知 | ・データベースのクエリログを分析し、処理に数秒以上かかっている重いSQL文を即座に特定できる ・「どのクエリがDB負荷を高めているか」をデータに基づいて判断し、インデックス追加などの対策が打てる |
CloudWatch Logs Insightsの活用で、ユーザー体験 (UX) を損なうボトルネックを早期に解消することができます。
AWSログ監視のコスト最適化|CloudWatch Logsの料金体系と削減戦略

CloudWatch Logsを利用する際は、料金体系を正しく理解してコストを抑える工夫が必要です。ここでは、CloudWatch Logsの料金体系やコスト削減のポイントを解説します。
CloudWatch Logsの料金体系の仕組み(無料枠・取り込み・保存・クエリ)
CloudWatch Logsの料金は、主に以下の要素で構成されます。
最新の料金体系は「Amazon CloudWatch 料金表」をご確認ください。 (*1)
| 無料利用枠 | ・毎月 5 GB 分のログデータ取り込み・保管・CloudWatch Logs Insightsクエリが無料で利用できる ・小規模環境の場合、無料枠だけで運用できる可能性がある |
| ログデータ取り込み (データ収集) 料金 | ・ログデータ取り込みの料金は$0.76 /GBとなる ・クラウド上に取り込んだログデータ量に応じて課金される ・ログデータの量に応じてボリュームディスカウントがある |
| ログデータ保存 (ストレージ) 料金 | ・ログデータの保存料金は$0.033 /GBとなる(圧縮されたデータの場合) ・CloudWatch Logs内に保存しているログデータ量に応じて課金される ・長期間保存する設定の場合、保存容量が増えてコストも増加する |
| CloudWatch Logs Insightsクエリ (分析) 料金 | ・クエリの料金は$0.0076 /GBとなる ・ログに対する検索クエリ実行量 (スキャンしたデータ量) に応じて課金される ・大規模ログへ頻繁な検索を行わない限り、通常の運用範囲ではわずかなコストで収まることが多い |
*1: 料金はアジアパシフィック (東京) リージョンです。
CloudWatch Logsの費用はログの取り込み量・保存量・分析量で決まります。したがって、コスト最適化の基本方針は「不要なログは取り込まない」「長期間保存しない」ことです。
CloudWatch Logsのコスト削減戦略2選
ログレベルの調整と不要ログのフィルタリングによる取り込みコスト削減
一般的に、もっとも負担が大きいのはログの取り込み費用です。削減するには、「どのログをクラウドに送るか」の取捨選択が重要となります。
具体的には、以下のような方法があります。
| ログレベルの適切な設定 | ・本番環境ではINFOまたはWARNレベル以上のログ出力にする ・必要最低限のログだけがCloudWatchに流れるようにロガー設定を見直す |
| CloudWatch Agent設定での除外フィルター | ・Agentの設定ファイルで、特定のパターン (正規表現等) を除外する ・ヘルスチェックなどの「大量に出るが重要度が低いログ」を無視する設定を行う ・無駄に取り込んでいるデータがないか見直す |
| Vended Logs側のフィルター設定 | ・正常な通信ログを捨てて、重要なイベントのみ残すことでコストを削減する ・AWSサービス (VPC Flow Logs等) の設定で、ログ出力量を調整する 例: VPC Flow Logsで拒否された通信のみを記録する |
以上のようなログレベル最適化とフィルタリングによってログの量を削減します。これにより、データ取り込み料金を必要最小限に抑えることが可能です。
まずは、DEBUGレベルのログ出力を見直し、徐々に不要なログパターンを洗い出してフィルタリングすることでコストの削減を進めましょう。
S3へのエクスポートとGlacierの利用による保存コスト削減
CloudWatch Logsの保存コストは、期間と容量に応じて増加します。一定期間を過ぎたログは削除し、低コストなストレージへ退避させましょう。
具体的な方法は次の通りです。
| CloudWatch Logsの保持期間設定 | ・各ロググループの保持期間を適切に設定する (90日等) ・期限を過ぎた古いログは自動的に削除されるため、容量の肥大化を防げる |
| ログのS3エクスポート | ・ログは、保持期間が過ぎる前にS3へエクスポートしてバックアップする ・バッチ処理の場合、コンソールやCLIを利用して圧縮ファイルとして出力する |
| S3からGlacierへの自動移行 | ・S3のライフサイクルルールを設定し、一定期間後はS3より低コストなGlacier (Deep Archive等) へ移行する ・Deep Archiveを使うことで、CloudWatch Logsの約30 分の1 以下の単価で長期保存が可能となる ・Glacierは、即時検索はできないが、監査対応用の保管としては十分に利用できる |
CloudWatch Logsに常時置いておくデータ量を減らし、高コストなホットストレージを節約できます。「短期監視はCloudWatch Logs、長期保管はS3・Glacier」という使い分けが重要です。これにより、監査要件 (長期保管) とコスト最適化を両立させることができます。
【シミュレーション 】コスト最適化戦略による削減効果
CloudWatch Logsを、従来の運用と、取り込み量の削減・保存先の変更を適用した最適化運用のコストをシミュレーションします。
シミュレーションの前提条件は次の通りです。
| ・リージョン: アジアパシフィック (東京) ・ログ量: 1 日あたり 100 GB (DEBUGレベルの詳細ログを含む) ・保存期間: 1 年間 (監査要件により保存必須) |
シミュレーションは月単位コストを算出し、結果は以下となりました。
| 従来の運用 | 最適化運用 | |
| 概要 | すべてCloudWatch Logsで管理してDEBUGログを含む全てのログを取り込んだ運用 | ログレベル調整で取り込み量を80 %削減 (20 GB/日) し、CloudWatch Logsには直近1ヶ月分のみ残して残りをS3 Glacier Deep Archiveへ移行した運用 |
| 取り込みコスト | 100 GB/日 × 30 日 × $0.76 = 約 $2,280 /月 ※ 不要なログも含めて全量課金される | 20 GB/日 × 30 日 × $0.76 = 約 $456 /月 ※ DEBUGログ抑制等により、取り込み費用が1/5に圧縮される想定 |
| 保存コスト | 36,500 GB × $0.033 = 約 $1,205 /月 ※ 高いストレージ単価で全データを保持し続ける | ・CloudWatch Logs分 (1ヶ月) : 600 GB × $0.033 = 約 $20 ・Glacier分 (11ヶ月) : 6,600 GB × $0.002 = 約 $13.2 ・合計 = 約 $33 /月 |
| 合計 | 約 $3,485 /月 | 約 $489 /月 |
※CloudWatch LogsおよびGlacier Deep Archiveへの保存データ量は、実際には圧縮されてさらに小さくなる場合があります。シミュレーションでは計算を簡略化するため、取り込み量ベースの単純計算を行っています。
シミュレーションの結果、取り込みコストは約80 %、保存コストは約97 %削減されました。月額の合計は約86 %削減されました。
ログ監視のコストは、適切な設計を行うことで大幅に削減可能です。コストを抑えながら監査要件を満たすためには、取り込み量の削減・保存先の変更が重要となります。
AWSログ監視のガバナンス強化: マルチアカウント集約と運用の自動化

企業利用のAWS環境では複数のAWSアカウントやリージョンを利用することが一般的です。その際、ログが各所に分散してしまい、統合的な監視や監査が難しくなる課題があります。
ここでは、ログの分散に対処するログ集約設計と、ログ監視結果を活用した運用自動化の方法について解説します。
これらの取り組みは、単なる監視効率化にとどまらず、組織全体で統制の取れたログ管理と運用ルールを実現する「ガバナンス強化」に直結します。
ログ集約設計を実現するAWS Organizations連携
AWSを企業が利用する場合、システムごとにAWSアカウントが分かれることがあります。また、ログが各アカウントやリージョンに分散してしまう課題があります。この課題の対策が、Organizationsを利用して組織全体のログを一箇所に集めるログ集約設計です。
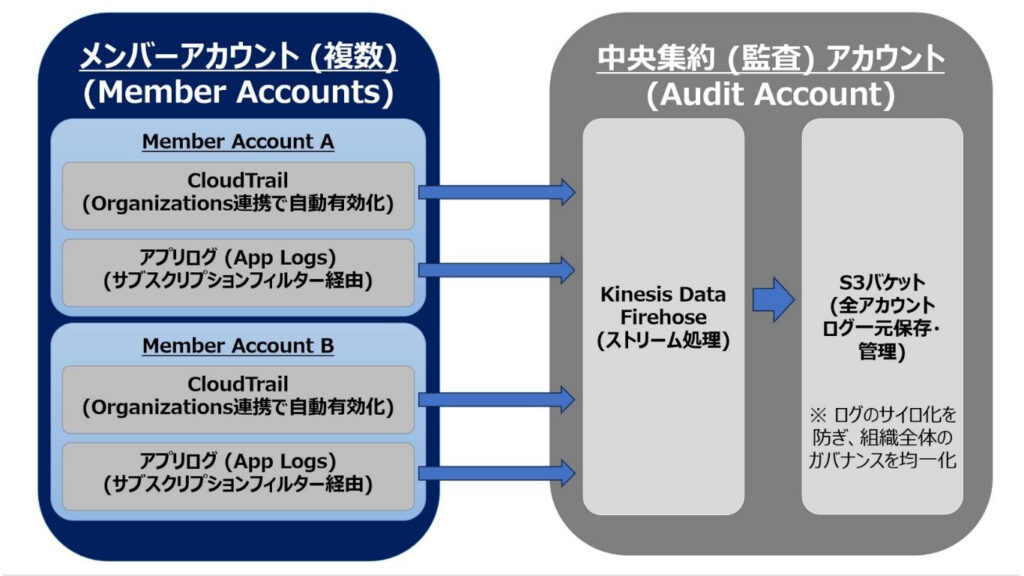
具体的な集約方法は以下の通りです。
| OrganizationsによるCloudTrailの自動集約 | ・Organizationsの機能を使い、組織内全アカウントの操作履歴 (CloudTrail) を一括有効化する ・ログの出力先に中央集約アカウント (監査アカウント) のS3を指定する ・メンバーアカウント側での設定変更や削除を防ぎ、監査ログの完全性を保つ |
| サブスクリプションフィルターとKinesisによる集約 | ・アプリログ等は、CloudWatch Logsの「クロスアカウント・サブスクリプションフィルター」を利用して転送する ・Kinesis Data Firehose (ストリーミングデータをS3や分析基盤へ自動配信するサービス) を経由させることで、大量のログをストリーム処理して集約用S3や分析基盤へ配送する |
| ガバナンス強化とセキュリティ運用の一元化 | ・組織全体のログを俯瞰できるため、アカウントを跨ぐ不審な動き (水平展開攻撃など) を検知する ・ログの保存ポリシーや監視ルールを中央で統一し、ガバナンスレベルを均質化する ・運用チームが単一のダッシュボードで一元管理できるようにして監視業務を効率化する |
ログを集約することで、サイロ化を防ぎ、組織全体のセキュリティとガバナンスを強力に維持することができます。
EventBridgeとLambdaによるアラート対応の自動化と標準化
EventBridgeとLambdaを組み合わせることで、障害発生時にインシデントを自動起票する仕組みも構築できます。
具体的な自動化の仕組みは以下の通りです。
| EventBridgeによるイベントの検知と集約 | ・CloudWatchアラームの状態変化や、GuardDutyの脅威検出結果をEventBridgeで受け取る ・AWS上の様々なイベントを一元的に集約するハブとして機能させる |
| EventBridgeのルール定義とLambdaの起動 | ・EventBridgeルールでイベント内容をフィルタリングし、特定のエラーコードや重要度が高いものだけを抽出する ・条件に合致した場合のターゲットとして、処理を実行するLambda関数を起動する |
| 外部システム連携による自動アクション | ・Lambda関数内でAPIを呼び出し、Slackへグラフ付きの詳細通知を送る ・JiraやBacklogなどのITS (インシデント管理システム) へ接続し、障害チケットを自動起票する |
この構成により、運用担当者の手動対応を排除し、対応フローを標準化・自動化することで組織として一貫性のある運用ガバナンスを実現できます。
IaC化による監視設定のコード化と管理(Terraform・CloudFormation)
CloudWatchアラームやメトリクスフィルターを手動で作成・管理すると、属人化リスクや運用負荷の増大を招きます。IaC化 (インフラ構成のコード定義・自動化) によって監視設定をコード管理することで、これらの課題を根本から解決できます。
具体的な実現方法は以下の通りです。
| TerraformやCloudFormationによるコード化 | ・以下の定義をCloudFormationテンプレート (AWSリソース構成を記述するテンプレート) 、またはTerraform設定ファイル (インフラ構成をコードとして記述するファイル) として記述する 例: アラーム、ダッシュボード、メトリクスフィルター等 ・Git (ソースコードなどの変更履歴を記録・管理するツール) でバージョン管理を行い、いつ・誰が・何を変更したかを追跡可能にする ・CI/CDパイプライン (コードのビルド・テスト・デプロイを自動化する仕組み) に組み込み、自動的にAWS環境へデプロイする |
| IaC化による運用の高度化 | ・設定がコード化されることで標準化が進み、コードレビューの作業フロー化が可能になる ・開発・検証・本番といった複数環境に対し、全く同じ監視設定を迅速に展開できる |
IaC化により、設定の「再現性」が担保され、手作業によるミスを排除した信頼性の高い監視基盤を構築できます。
AWSログ監視のセキュリティ・監査を強化するCloudWatch連携

AWSには監視・監査用途に特化したサービスがいくつか存在します。代表的なサービスはCloudWatch・CloudTrail・GuardDutyです。それぞれ役割が異なりますが、連携させることで多層的な防御と監視体制を築けます。
ここでは、CloudWatch Logsに加え、CloudWatch系イベント基盤であるEventBridgeとの連携も含め、各サービスの役割の違いを整理しながら具体的な連携方法を解説します。
監視・監査における各サービスの役割|CloudWatch・CloudTrail・GuardDuty
AWSの監視・セキュリティ運用を強固にするためには、CloudWatch・CloudTrail・GuardDutyの違いを正しく理解することが大切です。
各サービスは監視の視点が異なり、以下のように役割分担が明確に定義されています。
| CloudWatch | CloudTrail | GuardDuty | |
| 役割 | パフォーマンス監視とアプリケーションの動作状況の可視化 | API操作の証跡記録とコンプライアンス監査 | 自動化された脅威検知と悪意のあるアクティビティの検出 |
| 視点 | 今、何が起きているか | 誰が・何をしたか | 怪しい動きはないか |
| 特徴 | CPU使用率やエラーログなどをリアルタイムで収集し、システムの健全性を監視する | ユーザーアクティビティやAPI呼び出し履歴を記録し、いつ誰が設定変更を行ったかを追跡する | 機械学習を活用し、不正アクセスやコインマイニングなどの異常な通信を自動的に発見する |
各サービスは、単独で使うだけでなく連携させることで多層的な防御と監視を実現します。例えば「CloudTrailが記録したログをCloudWatchで監視する」といった構成が代表例です。
CloudWatch LogsによるCloudTrailのログ監視
CloudTrailの操作履歴ログをCloudWatch Logsと連携することで、セキュリティリスクをリアルタイムで検知する仕組みを構築できます。
連携の仕組みとメリットは以下の通りです。
| API操作ログのリアルタイム転送 | ・CloudTrailの設定で「CloudWatch Logsへの送信」を有効化することで、AWS上の全API操作履歴をCloudWatch Logsへ連携できる ・タイムラグのあるS3への保存と比較して、よりリアルタイムに近い速度でログを取り込める |
| セキュリティリスクの即時検知 | ・CloudWatch Logsのメトリクスフィルター (ログ内の特定パターンを検知して数値化する機能) を使用し、特定のリスクある操作をキーワード監視できる例: 「セキュリティグループの変更」が行われた瞬間にアラート通知される ・問題が起きた瞬間に気付く運用が可能になる |
CloudTrailとCloudWatch Logsを連携させることで、監査ログをアクティブに活用できるようになります。ただし取り込み・保存コストが発生するため、重要イベントのみをCloudWatch Logsに送り、詳細ログはS3に保存するといったコスト最適化の検討が必要です。
GuardDutyの検知結果をEventBridgeで通知
GuardDutyの検知結果をEventBridgeと連携させることで、迅速に通知する仕組みを構築できます。
連携の仕組みと設定方法は以下の通りです。
| GuardDutyによる脅威の自動検知 | ・機械学習を活用し、悪意のあるIPからのアクセスやマルウェアなどの脅威を自動的に検知する ・ログ設定を個別にチューニングしなくても、有効化するだけで環境全体の保護が可能となる |
| EventBridgeへのイベント発行とフィルタリング | ・GuardDutyが脅威を検知すると、EventBridgeに対してイベントが発行される ・EventBridgeルールを作成し、検出結果の中でも重要度が「高」または「中」のものだけをフィルタリングする |
| 担当者への迅速な通知と自動対応 | ・ルールのターゲットとしてSNSを指定し、セキュリティ担当者にメールやSlackで即時通知する ・Lambdaを指定すれば、IP遮断などの自動対応を行うことも可能となる |
GuardDutyとEventBridgeを組み合わせることで、脅威の発見から初動対応までの時間を大幅に短縮できます。
AWSログ監視はCloudWatchだけで十分か?SaaSツールとの比較と使い分け

近年はDatadogやSplunk、New RelicといったサードパーティのSaaS監視ツールも多く利用されています。そのため「AWSログ監視はCloudWatchだけで十分なのか?」と悩むケースも少なくありません。
本章では、CloudWatch単独運用時の注意点と、SaaS監視ツールが適するケースの使い分けについて解説します。
CloudWatch単体運用の限界と注意点
CloudWatchはAWSネイティブであり、設定不要でメトリクスが取れるなど非常に強力なサービスです。
しかし、単体ですべての要件を満たそうとすると、以下の点で機能不足や運用の難しさを感じる場合があります。
| ログ相関分析の難易度 | アプリ・インフラを横断した複雑な分析は、SaaSツールと比較して直感的な操作やドリルダウンが難しい場合がある |
| APM (分散トレーシング) の機能差 | X-Ray (アプリの分析・追跡サービス) も利用可能だが、SaaS系APMツールに比べて導入の手軽さや機能の豊富さで劣るケースがある |
| ダッシュボードの表現力 | 高度な可視化やカスタマイズ性には限界があり、専用SaaSツールほど柔軟なグラフ表現ができない場合がある 例: ビジネス指標とシステム指標の複雑な組み合わせなど |
CloudWatchの単体運用の課題を理解して、SaaSツールの採用を検討することも大切です。
CloudWatchを軸にしたSaaS監視ツールの併用・使い分け|使い分け一覧表付き!
SaaSツールを使うことで、CloudWatchの弱点を補完できる場合があります。
主なSaaSツールにはDatadog・Splunk・New Relicがあり、以下のケースではSaaSツールの利用も選択肢となります。
| ・AWSだけでなく、Azure・GCP・オンプレミス環境も統合して監視したい場合 ・ログの取り込みから分析、機械学習による異常検知までをシームレスに行いたい場合 ・リッチなダッシュボード・サービスマップ・コードレベルの分散トレーシング (APM) を重視する場合 |
SaaSツールは機能が豊富な分、コストが高額になる傾向があります。コストと機能のトレードオフを考慮し、両者を併用するのも選択肢の一つです。全リソースの基本監視はCloudWatchで行い、本番アプリのAPM分析のみSaaSツールを使うといった使い分けも有効です。
▼CloudWatchとSaaS監視ツールの使い分け例
| 監視構成の選択パターン | 適しているケース | 主な特徴・ポイント |
| CloudWatchだけで十分なケース | ・監視対象がAWS環境のみ ・基本的なログ監視・アラート通知が目的 ・障害検知と一次対応を重視 ・詳細なAPMや分散トレーシングは不要 ・コストをできるだけ抑えたい | ・AWSネイティブで構成がシンプル ・初期設定や運用負荷が低い ・コストを最小限に抑えやすい |
| CloudWatchを軸にSaaSツールを併用するケース(最も一般的) | ・AWS+他クラウド/オンプレの統合監視 ・本番システムのみ詳細なAPM分析が必要 ・ログ・メトリクス・トレースの相関分析を重視 ・障害解析や性能ボトルネックを効率化したい | ・基本監視はCloudWatchで実施 ・重要アプリのみDatadog / New Relicなどを利用 ・コストと可視性のバランスが取りやすい |
| SaaS監視ツール中心に構成するケース(例外) | ・マルチクラウド・オンプレを含む大規模環境 ・マイクロサービス構成で分散トレーシング必須 ・SREチームによる高度な可観測性を重視 ・ビジネス指標と技術指標を統合した分析が必要 | ・高度な可視化・分析が可能 ・導入・運用コストは高め ・CloudWatchも補助的に併用されることが多い |
多くのAWS環境では、CloudWatchをベースとしたログ監視を行いながら、必要な範囲にのみSaaS監視ツールを併用する構成が採用されています。
監視の目的・システム規模・コスト制約に応じて、最適な使い分けを検討することが重要です。
まとめ
本記事では、AWSログ監視の設計手法について、基本概念からコスト削減、セキュリティ強化まで幅広く解説しました。
AWS環境の監視は、一度設定して終わりではありません。ビジネスの変化に合わせて継続的に見直し、最適化していくことが求められます。まずは自社の現状を把握し、最小構成からログ監視を強化していきましょう。
クラウドサーバーの構築支援なら、国内25,000 人以上 (※1) の技術者を擁し、大手企業を中心に2,555社との取引実績 (※2) を持つ株式会社テクノプロにお任せください。AWS導入の準備段階からビジネス設計、本稼働、運用まで、一括して任せることができます。
※1: 2024年6月末時点
※2: (株) テクノプロ及び (株) テクノプロ・コンストラクション 2024年6月末時点
監修者
テクノプロ・ホールディングス株式会社
チーフマネージャー
中島 健治
2001年入社
ITエンジニアとして25年のキャリアを持ち、チーフマネージャーとしてテクノプロ・エンジニアリング社にて金融・商社・製造業など多業界でのインフラ基盤構築に従事してきた。2008年から2024年まで、オンプレミス環境でのストレージ・サーバ統合基盤の設計・構築を手掛け、特に生成AI・データ利活用分野のソリューション開発実績が評価されている。現在は技術知見を活かしたマーケティング戦略を推進している。






