機械学習 (コンピューターがデータからパターンを学習し予測する技術) は、DX推進の中核を担う技術です。蓄積された膨大なデータから将来の動向を予測し、迅速に意思決定を行うことは、企業が競争力を維持するうえで重要な要素です。
本記事では、AWSが提供する機械学習の主なサービスを比較し、モデル開発の核となるSageMakerにおける導入メリットや料金体系について解説します。また、AWSの機械学習を「自社システムにどのように組み込むか」「内製で運用できるか」を検討している企業担当者に向けて、サービス選定の考え方から導入・運用のポイントまでを整理しています。
これらを把握することで、AWS上で機械学習プロジェクトを成功させるための具体的な道筋が明確になるでしょう。
AWS環境で機械学習の導入をお考えの際は、幅広い業種や業態のニーズに対応した豊富な実績を持つ株式会社テクノプロへご相談ください。それぞれの目的に合った機械学習の構築・運用をご提案いたします。
テクノプロはAWSの構築から運用まで幅広く支援しています
AWSの機械学習とは?

機械学習とは?
機械学習 (ML) とは、コンピューターがデータから自動的にパターンを学習し、予測や判断を行う技術です。従来のプログラミングは人間がルールを記述していましたが、機械学習はデータから自動的にルールを生成します。
従来のアプローチと機械学習の違いをまとめました。
| 項目 | 従来のプログラミング | 機械学習 |
| ルールの設定 | 人間がコードで記述 | データから自動生成 |
| 必要な要素 | 明確な論理 (命令文・コード) | 大量の学習データ |
| 得意な処理 | 定型的な計算・事務 | 予測・分類・検知 |
従来のプログラミングは定型処理に強く、機械学習はパターン認識や予測など、明確なルールで記述しにくい処理に優れています。機械学習によって、業務を自動化できる範囲が大きく広がります。
ビッグデータの蓄積と計算リソースの低価格化により、機械学習のビジネス活用が容易になりました。機械学習は大量の情報を処理し、未知の事象に対しても精度の高い分析が可能であるため、ビジネスの現場で重視されています。
AWSの機械学習の特徴と全体像
AWSの機械学習は、研究用途だけでなく、企業が自社データを活用して業務システムに組み込むことを前提に設計されています。そのため、企画・開発・運用といった機械学習のライフサイクル全体を見据えたサービス体系が用意されています。
単一のツールではなく、用途やフェーズに応じて複数のサービスを組み合わせて利用できる点が特徴です。
| 観点 | 特徴の要点 |
| サービス構成 | データ保存・前処理・学習・推論・監視などを、役割ごとに分かれたサービスの組み合わせで構成 |
| AI/MLの提供形態 | 学習済みモデルを使うAIサービスと、独自モデルを構築するMLサービスを明確に分離 |
| 開発から運用までの流れ | 実験環境と本番環境を同一基盤で扱え、継続的な改善を前提に設計可能 |
このようにAWSの機械学習は、「どう作るか」「どう育てるか」を前提に整理されたサービス構造を持っています。
AWSで機械学習を行う3つのメリット

AWS環境の機械学習は、インフラ構築工数を削減し、ビジネスの成長に合わせた柔軟な拡張が可能になります。多くの企業がAWSの機械学習を利用してビジネスを推進しています。
ここでは、AWSの機械学習を導入するメリットを紹介します。
柔軟なリソース確保と構成変更が可能
機械学習の導入時には、「どの程度の計算リソースが必要かわからない」「検証と本番で必要な性能が大きく変わる」といった課題がよくあります。
こうした不確実性に対して、AWSでは数クリックで機械学習に必要な計算リソースを確保でき、プロジェクトの進行に応じて必要な分だけ柔軟に変更できる環境が整っています。
AWSにおけるリソース確保と構成変更の特徴は以下の通りです。
| 調達スピード | 物理サーバーの手配が不要で、数分で実行環境を構築できる |
| 多様な選択肢 | 用途に合わせて多種多様なインスタンス (CPU・GPU等) から選択できる |
| 柔軟な変更 | 規模拡大に合わせて構成をオンデマンドで変更できる |
AWSは、自社で機材を保有・管理する負担なく最新のハードウェアをすぐに利用できます。物理的な納期を待たずに実験を開始できるスピード感のあるシステム構築が可能なことも大きなメリットで、開発の試行錯誤を繰り返す機械学習プロジェクトに向いています。
AWSには機械学習向けに最適化された独自プロセッサーを含む、豊富なインスタンス選択肢があり、こうした柔軟性を支えています。
AWSの従量課金制と無料利用枠でコストを最適化できる
機械学習は成果が出るまでに試行錯誤が必要なため、「初期投資が大きくなりがち」「費用対効果が見えにくい」という課題があります。
この課題に対し、AWSではスモールスタートを前提とした料金体系により、大規模な予算を事前に確保することなく、少ない投資で機械学習の効果を検証しながら導入を進めることができます。
これは、AWSは初期費用を抑え、以下のように利用実態に合わせた柔軟なコスト管理を実現しているためです。
| 初期投資の抑制 | 物理サーバーの購入費が不要で、小規模な構成から開始できる |
| 無料利用枠の活用 | 特定のサービスを一定範囲内で無料試用し、機能を検証できる |
| 従量課金制 | リソースを使用した時間や量に応じて支払うため、無駄な支出を抑えられる |
| リスクの低減 | 実験的な試行錯誤にかかるコストを最小限に留められる |
従量課金の仕組みにより、プロジェクトの停止や変更にも柔軟に対応でき、限られた予算内でも効率的に機械学習を推進できます。
データの保存から加工・分析まで必要な機能が揃っている
機械学習プロジェクトでは、「データ基盤の構築が複雑」「前処理やセキュリティ設計に工数がかかる」といった課題が発生しがちです。
AWSでは、機械学習に必要なデータの蓄積・加工・分析といった周辺機能があらかじめ統合されており、サービスを組み合わせることで単一の環境で完結できるため、構築や運用の負担を大きく軽減できます。
AWSにおける主な機能連携の特徴は以下の通りです。
| データの蓄積 | S3により大量の学習データを安全かつ安価に保存できる |
| データの加工 | Glueを利用して学習前の複雑なデータ整形を自動化できる |
| サービス間の親和性 | 各サービスが標準で統合されており、スムーズなデータ連携が可能 |
| 強固なセキュリティ | 共通の認証基盤で権限管理を一元化し、データの安全性を確保できる |
これらの機能がAWS内で統合されていることで、インフラ構築の手間を減らし、データの移動に伴うセキュリティリスクや設計の複雑さを抑制できます。その結果、エンジニアはデータ準備に追われることなく、モデルの構築や精度向上といった本来注力すべき作業に集中できます。
AWSの機械学習サービス | 2つの主要な分類
AWSの機械学習サービスは、開発経験の少ない担当者でも最適なツールを選択できる環境が整っています。担当者のスキルや目的に応じて大きく2つのカテゴリーに分類されます。
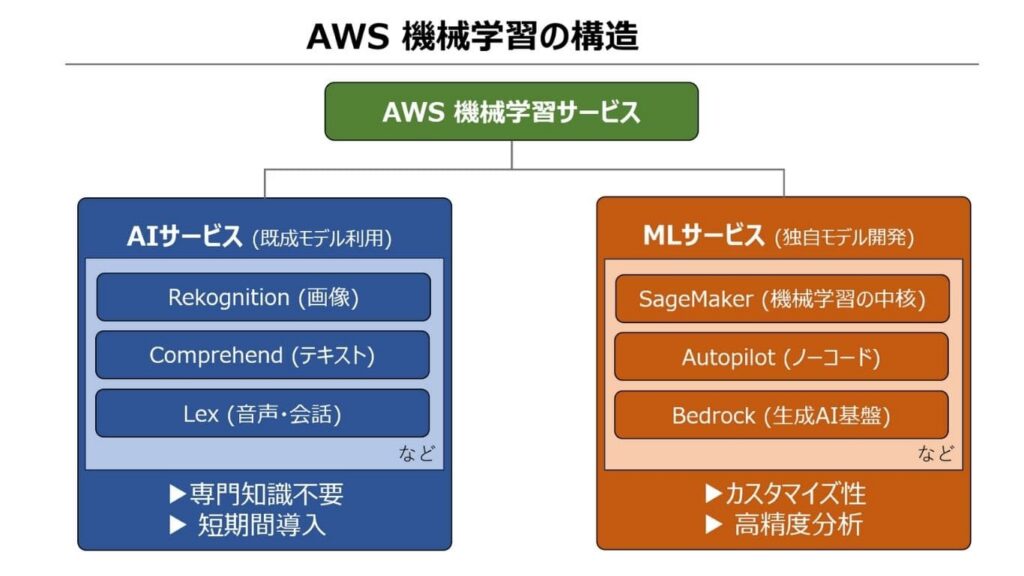
機械学習初心者でも手軽に活用できる「AWS AI サービス」
AWSのAIサービスは、機械学習の専門知識がなくてもAPIを呼び出すだけで高度なAI機能をアプリケーションに組み込めます。
AIサービスの特徴は以下の通りです。
| 専門知識が不要 | 複雑なアルゴリズムの理解やモデルの構築をせずに、既存のアプリへAI機能を統合できる |
| 学習データが不要 | AWSが事前に膨大なデータで学習させたモデルを利用するため、自社でデータを用意する手間が省ける |
| 導入のスピード | APIと連携させてAIを動かすことができるため、短期間でのプロトタイプ作成や本番導入できる |
自社でモデルを学習させる必要がなく、サービス側が提供する機能をそのまま活用できるため、機械学習の専門チームを組織しなくても、ビジネスに最新のAI技術を取り入れることが可能です。
画像認識・音声変換・テキスト分析といった特定の機能において、開発コストを抑えながら迅速に実装したい場合に適しています。
具体的なサービスの種類については「4.AWS 機械学習の主なAIサービスと特徴」で詳しく解説します。
エンジニアが本格的な開発・運用を行う「AWS ML サービス」
AWSのMLサービスは、独自のデータを用いて機械学習モデルの作成・学習・デプロイ (開発したモデルを使える状態に配置する) を行うための開発者向け基盤です。
MLサービスの特徴は以下の通りです。
| 独自のデータ活用 | 自社固有のデータを用いて、ビジネス課題に特化したモデルを作成できる |
| 自由度の高いカスタマイズ性 | AIの計算ルール (アルゴリズム) の選択や調整を自由に行い、精度の追求ができる |
| 運用の効率化 | モデルの学習から本番環境へのデプロイまで、一連の工程を一元管理できる |
AIサービスが既存の仕組みを利用するのに対し、MLサービスは自社専用のモデルを構築する際に利用します。既存の製品では対応が難しい特殊な業務要件や、高い予測精度が必要なプロジェクトに向いています。
また、AWSのMLサービスでは、中核となるSageMakerを活用することで、エンジニアはインフラ管理の手間を省きつつ、高度なモデル開発に注力できます。
独自の計算手法を用いて、自社の競争力につながる機械学習モデルを構築したい場合に適した選択肢です。
具体的なサービスや機能については「5.AWSの主なMLサービスと特徴」で詳しく解説します。
AWS AI/MLサービスの選び方【目的・スキル別】
AWSにおける機械学習サービスは、開発工数 (導入スピード)・専門スキルの有無・カスタマイズの必要性という3つの軸が選定基準となります。
利用者の目的や状況に応じたサービス選定の考え方は以下の通りです。
| AWS AIサービスを選ぶケース例 | ・画像認識や翻訳など、汎用的な機能を短期間で実装したい ・機械学習の専門知識を持つエンジニアが不足している ・自社で学習データを用意するのが難しい |
| AWS MLサービスを選ぶケース例 | ・自社独自のデータを用いて、高い予測精度を実現したい ・既存のAIサービスでは対応できない特殊な業務要件がある ・モデルの計算アルゴリズム自体を細かくチューニングしたい |
このように、開発スピードを重視するか、独自性や精度を重視するかによって、選択すべきサービスは異なります。
各サービスの主な違いは、以下の表の通りです。
| 項目 | AWS AIサービス | AWS MLサービス |
| 推奨する利用者 | アプリ開発者・ビジネス担当者 | データサイエンティスト・機械学習エンジニア |
| 開発期間 | 短い (API連携のみ) | 中〜長期 (モデルの学習・評価が必要) |
| カスタマイズ性 | 低い (提供機能の利用) | 高い (一から構築・調整が可能) |
| 学習データの準備 | 不要 | 必要 |
最初はAIサービスでスモールスタートし、より高度な要件や独自性が必要になった段階でSageMakerなどのMLサービスを検討するのが効率的な進め方です。
AWS 機械学習のAIサービス一覧と特徴

AWSのAIサービスは、用途やビジネス課題に合わせて多岐にわたるラインナップが用意されています。これらは機能ごとにカテゴリー分けされており、自社の目的に合ったサービスをパズルのように組み合わせることで、高度なシステムを短期間で構築できます。
本章では、AWSの主なAIサービスを用途別に整理しています。まずは以下の一覧から、関心のあるカテゴリを確認し、該当箇所をご覧ください。
| カテゴリ | 主な用途 | 主なサービス |
| コンピュータビジョン系 | 画像・動画解析 | Amazon Rekognition / AWS Panorama |
| データ抽出・分析系 | OCR・文書理解 | Amazon Textract / Amazon Comprehend / Amazon Augmented AI |
| 言語・会話型AI系 | 音声認識・翻訳・対話 | Amazon Lex / Amazon Transcribe / Amazon Polly / Amazon Translate |
| カスタマーエクスペリエンス向上系 | 検索・レコメンド | Amazon Kendra / Amazon Personalize |
| ビジネスメトリクス・予測系 | 需要予測・異常検知 | Amazon SageMaker(Canvas) |
| 開発効率化系 | コード・運用支援 | Amazon DevOps Guru / Amazon Q Developer |
| 産業・ヘルスケア分野特化型 | 予知保全・IoT | Amazon Lookout for Equipment / AWS IoT SiteWise |
コンピュータービジョン系 | Rekognition・Panorama
コンピュータービジョンとは、画像や動画から有益な情報を抽出する技術です。AWSでは、一般的な画像分析から工場での検品まで、シーンに合わせたサービスが提供されています。
AWSにおけるコンピュータービジョン系の主なサービスと特徴は以下の通りです。
▼Rekognition
| 特徴 | 画像や動画内の物体・シーン・顔・テキストなどを自動で検出・分析するサービス |
| 活用例 | 本人確認 (eKYC) における顔認証や、不適切な画像コンテンツの自動フィルタリング |
▼Panorama
| 特徴 | ネットワークカメラの映像を専用デバイスでリアルタイムに分析するためのサービス ※ AWS Panoramaは、2026年5月31日にサポートの終了が決定しています。 詳細はAWSの公式ページをご確認ください。 |
| 活用例 | 工場の安全管理や店舗の動線分析など、現場での低遅延な画像解析を実現 |
AWSのAIサービスを利用することで画像や動画データの解析を自動化できます。これにより、今まで人の目に頼っていた検品や監視業務を効率化し、ビジネスの安全性を高めることが可能です。
データ抽出・分析系 | Textract・Comprehend・A2I
データ抽出・分析系のサービスは、AIによる抽出・分析と、必要に応じた「人の目による確認」を組み合わせることで、業務プロセスの自動化を高い精度で実現できます。
AWSにおけるデータ抽出・分析系の主なサービスは以下の通りです。
▼Textract
| 特徴 | ・単なるOCR (文字認識) ではなく、文書内の構造 (表組みや入力フォームの形式) を維持したままデータを抽出可能 ・手書き文字の読み取りにも対応しており、多様な書類をデジタル化できる ・複雑な事前設定なしで、スキャン画像やPDFから即座にテキストを抽出 |
| 活用例 | ・請求書や領収書の自動読み取りによる経理業務の効率化 ・手書きの申込書からのデータエントリー自動化 |
▼Comprehend
| 特徴 | ・テキストデータから、感情 (ポジティブ・ネガティブ) や重要なキーワードを抽出する自然言語処理サービス ・文脈を理解し、人名・地名・組織名などの「エンティティ」や個人情報を自動で分類・検出 ・複数の言語に対応しており、大量の文章からビジネスに役立つ知見を抽出 |
| 活用例 | ・コールセンターに届く問い合わせ内容の自動分類や、顧客満足度の傾向分析 ・SNSの投稿内容から自社製品に対する評判を調査するソーシャルリスニング |
▼A2I (Augmented AI)
| 特徴 | ・機械学習の予測結果を、人間が目視確認するためのワークフローを簡単に構築できるサービス ・「AIの確信度が低い (迷っている) 場合だけ人間に回す」という条件分岐が自動化できる ・ TextractやRekognitionなどのAWSサービスと標準で統合されており、導入が容易 |
| 活用例 | ・Textractで読み取った重要書類の最終確認フロー ・Rekognitionが検知した「不適切なコンテンツ」の最終的な公開可否判断 |
これら3つのサービスは連携させることで、データの抽出・分析・品質管理を一貫したワークフローとして構築できます。高い信頼性が求められる業務においても、AIのスピードと人間の正確さを両立させた、実用性の高いシステム開発が可能です。
言語・会話型AI系 | Lex・Transcribe・Polly・Translate
言語・会話型AI系のサービスは、音声データのテキスト化や、多言語展開を支援します。
AWSにおける言語・会話型AI系の主なサービスは以下の通りです。
▼Lex
| 特徴 | ・Alexaと同じ技術を用いた、音声やテキストによる会話型インターフェースを構築するサービス ・自動音声認識 (ASR) と自然言語理解 (NLU) により、複数の言語や表現方法でも顧客の意図を理解可能 ・Amazon Connect、Lambda、DynamoDB など他のAWSサービスとシームレスに統合でき、バックエンドのビジネスロジックと連携 ・生成AI (LLM) との統合により、より自然で文脈に応じた会話が可能 |
| 活用例 | ・FAQへの自動応答や顧客サポート窓口の24時間対応 ・コールセンターで一般的な問い合わせを自動処理し、必要に応じてオペレーターにエスカレーション ・ホテルやレストランの予約、注文状況の確認、配送日の変更などを自動化 |
▼Transcribe
| 特徴 | ・音声データを高精度なテキストに自動変換する (文字起こし) サービス ・複数人の話者を識別し、誰が何を話したかを区別して記録可能 ・専門用語の辞書登録機能により、業界特有の用語も正しく認識 |
| 活用例 | ・コールセンターの通話録音のテキスト化と分析 ・動画コンテンツへの自動字幕付与 |
▼Polly
| 特徴 | ・テキストデータを自然な人間の声 (音声) に変換するサービス ・多言語および多様な話者の声を選択でき、イントネーションの調整も可能 ・リアルタイムの音声合成により、動的なコンテンツにも対応 |
| 活用例 | ・ニュース記事やブログ記事の音声読み上げ機能 ・公共施設やコールセンターの自動音声案内 |
▼Translate
| 特徴 | ・高品質で自然な機械翻訳を提供するサービス ・文脈を理解した翻訳により、従来の機械翻訳よりも精度が高く、多言語に変換できる ・カスタム用語集を利用することで、独自の固有名詞や専門用語も正確な翻訳が可能 |
| 活用例 | ・Webサイトやアプリケーションの多言語対応 ・多言語でのカスタマーサポートメールの翻訳支援 |
これら音声や翻訳に関するサービスを組み合わせることで、言語の壁を越えたコミュニケーションや、情報の多角的な活用が可能です。
カスタマーエクスペリエンス向上系 | Kendra・Personalize
カスタマーエクスペリエンス (CX) 向上系のサービスは、膨大な情報の中から「ユーザーが本当に求めているもの」をAIが先回りして提示することで、顧客満足度やサイトの回遊率を高めます。
カスタマーエクスペリエンス向上系の主なサービスは以下の通りです。
▼Kendra
| 特徴 | ・機械学習を用いた高度なセマンティック検索 (文脈や意図を汲み取った検索) を実現するサービス ・S3やSharePoint・Salesforce・ウェブサイトなど、散在する社内外のデータソースを横断的に検索が可能 ・最新の生成AI (RAG) のデータ基盤としても活用され、社内ドキュメントに基づいた正確なAI回答の生成を支える |
| 活用例 | ・エンタープライズ検索で、社内規定や技術資料の膨大なアーカイブから、知りたい情報を自然言語で即座に発見 ・カスタマーサポート:顧客からの問い合わせに対し、マニュアルから最適な回答箇所を自動で抽出して提示 |
▼Personalize
| 特徴 | ・Amazon.comで培われたレコメンデーション技術を、自社のアプリやサイトに短期間で導入できるサービス ・クリック履歴や購入履歴などの行動データをリアルタイムに分析し、ユーザーごとに最適化された「おすすめ」を提示 ・機械学習の専門知識がなくても、用途 (Eコマース・動画配信など) に合わせた最適なレシピ (アルゴリズム) を選択するだけで運用が可能 |
| 活用例 | ・ECサイトや動画配信サービスにおける、ユーザーの好みに合わせた「あなたへのおすすめ」や「次にこれを見ませんか?」の表示 ・パーソナライズされたマーケティングにおける特定のユーザー層に刺さるクーポン配信や、メールマガジンのコンテンツ最適化 |
Kendraは「能動的に探す」、Personalizeは「受動的に提案される」といった使い方を組み合わせることで、ユーザーのストレスを最小限に抑えた快適なデジタル体験を提供できます。
ビジネスメトリクス・予測系 | SageMaker
ビジネスメトリクス・予測系のサービスは、過去のデータから未来を予測したり、異常な変化をいち早く検知したりすることで、データに基づいた迅速な経営判断を支援します。現在は、ノーコードで高度な予測ができるSageMaker (Canvas) への統合が進んでいます。
ビジネスメトリクス・予測系の主なサービスは以下の通りです。
▼SageMaker
| 特徴 | ・プログラミングや機械学習の専門知識がなくても、マウス操作だけで高精度な予測モデルを構築可能 ・従来のForecastやFraud Detectorの機能を内包しており、時系列予測や不正検知など多様な課題に対応 ・既存の売上データや顧客データ (CSV等) をアップロードするだけで、数分で将来の数値予測を実行 ・生成AI (LLM) と連携し、データの中身について自然言語で質問しながら分析することも可能 |
| 活用例 | ・小売・製造業における在庫の最適化や、スタッフのシフト配置計画の策定 ・金融取引における不正利用の検知や、ユーザーの解約率の予測 |
これら予測・検知系のサービスを活用することで、「データ」に基づいた攻めの経営と、守りのリスク管理を両立させることが可能です。
開発効率化系 | DevOps Guru・Amazon Q Developer
開発効率化系のサービスは、AIがソースコードの品質チェックやシステムの運用状況の監視を補助することで、エンジニアの工数削減とシステムの信頼性向上を同時に実現します。
開発効率化系の主なサービスは以下の通りです。
▼DevOps Guru
| 特徴 | ・AWS上のアプリケーションやインフラの稼働状況を分析し、異常の兆候をAIが自動で検知する運用支援サービス ・膨大なログやメトリクスの中からノイズを排除し、対処が必要な「真の問題」だけを特定して通知 ・問題の根本原因の推定と、推奨される解決策 (修復手順) を提示することで、システム復旧までの時間を短縮 |
| 活用例 | ・データベースの急激な遅延や、サーバーレス関数のタイムアウトといった異常のリアルタイム検知 ・複雑な分散システムにおける、監視設定の自動化とアラート対応の効率化 |
▼Amazon Q Developer
| 特徴 | ・CodeGuruの機能を継承・進化させた、次世代のAI開発アシスタント ・チャット形式でのコード生成や、既存コードのバグ修正・リファクタリングの提案が可能 ・セキュリティの脆弱性スキャン機能により、コード公開前にリスクを自動検知して修正案を提示 ・Javaのバージョンアップといった、大規模なコードのアップグレード作業も自動化を支援 |
| 活用例 | ・対話型AIを活用したプログラミングの高速化 (コードの自動補完や解説) ・開発プロジェクト全体のセキュリティ品質の向上と、レビュー工数の削減 |
これら開発・運用をサポートするAIを活用することで、人的ミスを最小限に抑えながら開発サイクルを加速させ、より付加価値の高い業務に集中できる環境を構築できます。
産業・ヘルスケア分野特化型 | Lookout for Equipment・IoT SiteWise
産業・ヘルスケア分野特化型のサービスは、特定の業界や現場が抱える固有の課題を解決します。特に製造現場やプラントにおいて、AIを活用した「予知保全」を専門知識なしで実現し、生産停止リスクを最小限に抑えます。
産業・ヘルスケア分野特化型の主なサービスは以下の通りです。
▼Lookout for Equipment
| 特徴 | ・既存の設備に設置されているセンサーデータ (圧力・流量・温度など) を活用し、機器の異常を検知するサービス ・多数のセンサーデータを同時に分析し、人間では気づけない微細な挙動の変化から故障の予兆を特定 ・異常検知時には「どのセンサーが要因となっているか」を提示するため、原因究明と修理の時間を大幅に短縮可能 ※ 2026年10月7日にサービス終了が決定しています。詳細はAWSの公式ページをご確認ください。 |
| 活用例 | ・発電所や化学プラントにおける、大型ポンプやコンプレッサー・タービンの予知保全 ・製造ラインの重要設備に対するダウンタイム削減と、メンテナンス計画の最適化 |
▼IoT SiteWise
| 特徴 | ・産業用プロトコル (OPC UA・Modbus TCP等) に対応し、工場の設備からセンサーデータを収集・蓄積・可視化するサービス ・多変量異常検知機能により、機械学習の専門知識なしで複数センサーの異常の自動検出が可能 ・AWS IoT SiteWise Edge により、オンプレミスのエッジデバイスでのリアルタイム処理も可能 ・生成AI (AWS IoT SiteWise Assistant) による自然言語でのデータ分析も可能で、技術知識がない作業者も簡単に情報活用が可能 |
| 活用例 | ・センサーデータから異常を自動検知し、予知保全による計画外のダウンタイム削減 ・過去の故障データと現在の稼働データを組み合わせた、より高度な分析や将来予測の基盤構築 |
こうした現場特化型のAI技術を活用することで、従来の「壊れてから直す」対応から「壊れる前に処置する」データ駆動型の運用への転換が可能です。
AWS機械学習の主要MLサービス一覧と特徴

AWSのMLサービスは、独自の機械学習モデルを効率的に構築・学習・デプロイするための環境を提供します。汎用的なAIサービスでは対応しきれない、自社固有のデータに基づいた高度な分析や、完全カスタマイズされた予測システムの開発を支援します。
AWSのMLサービスは、SageMakerを中心に、データ準備から運用・監視までをカバーする複数のサービスで構成されています。まずは以下の一覧で全体像を確認し、関心のある領域から読み進めてください。
| 分類 | 役割 | 主なサービス |
| ML開発基盤 | モデルの構築・学習・デプロイ | Amazon SageMaker |
| ノーコード・自動化 | PoC・高速立ち上げ | Amazon SageMaker Canvas / Amazon SageMaker Autopilot / Amazon SageMaker JumpStart |
| データ準備・管理 | 特徴量・教師データ整備 | Amazon SageMaker Data Wrangler / Amazon SageMaker Feature Store / Amazon SageMaker Ground Truth |
| モデル監視・最適化 | 精度・公平性・運用品質 | Amazon SageMaker Model Monitor / Amazon SageMaker Debugger / Amazon SageMaker Clarify |
| 生成AI基盤モデル | LLM活用・RAG・Agent | Amazon Bedrock |
ML開発基盤 | SageMaker
AWSのML開発基盤は、機械学習のワークフロー全体をカバーするサービスです。AWSは、インフラの管理を担うと共に、高性能なモデル開発に集中できる環境を提供します。
ML開発基盤の中核となるサービスはSageMakerです。特徴は以下の通りです。
▼SageMaker
| 特徴 | ・機械学習の全工程 (データの準備・モデルの構築・学習・デプロイ・管理)を一通りサポートしている ・Jupyter Notebookなどの統合開発環境が用意されており、セットアップなしですぐに開発を開始できる ・計算リソース (サーバー) の自動スケーリング機能により、大規模なデータ学習も短時間かつ効率的に実行できる ・学習済みモデルをAPIとして簡単にデプロイでき、作成したモデルを素早くビジネスに適用できる |
| 活用例 | ・製造・医療現場における、自社独自の画像データを用いた高精度な異常検知・診断モデルの構築 ・大規模なECサイトにおける、ユーザーの複雑な行動ログに基づいた高度な予測エンジンの開発 |
SageMakerは、機械学習における面倒なインフラ管理を解消し、モデルの品質向上に専念できるプラットフォームです。従来数ヶ月かかっていた開発サイクルを大幅に短縮し、ビジネスへの機械学習導入を迅速に推進できます。
ノーコード・自動化ツール | Canvas・Autopilot・JumpStart
ノーコード・自動化ツールは、プログラミングや機械学習の専門知識は必要ありません。誰でも迅速にAI・MLの恩恵を受けられるようにするためのツール群です。
AWSにおける主なノーコード・自動化ツールは以下の通りです。
▼Canvas
| 特徴 | ・ブラウザ上の視覚的な操作 (ドラッグ&ドロップ) のみで、機械学習モデルの構築や予測が可能なノーコードツール ・データの加工からモデルの学習・予測結果の生成までをビジネスユーザー自身で完結できる ・最新の生成AI機能とも統合されており、自然言語でのデータ分析や基盤モデルを活用したアプリ開発にも対応 |
| 活用例 | ・過去の販売データに基づいた在庫需要の予測や、顧客の解約リスクの分析 ・社内の非構造化データ (テキストなど) から、チャット形式で情報を抽出・要約するシステムの構築 |
▼Autopilot
| 特徴 | ・データの性質に合わせて、最適なアルゴリズムの選定やパラメータ調整をAIが完全自動で行うAutoML (自動機械学習) 機能 ・プロセスの透明性が高く、AIが作成したモデルのソースコードやノートブックを確認・編集することが可能 ・精度重視のアンサンブルモードや、実行速度重視のハイパーパラメータ最適化など、用途に合わせたモード選択ができる |
| 活用例 | ・専門チームが不在のプロジェクトにおける、高精度な予測モデルの迅速な立ち上げ ・データサイエンティストがモデルのプロトタイプ (試作) を作成する際の工数削減 |
▼JumpStart
| 特徴 | ・業界標準の学習済みモデルや、最新のオープンソースモデル (LLMなど) を数クリックでデプロイできるハブ機能 ・特定のビジネス課題 (画像分類・テキスト要約・感情分析など) に対応したテンプレートが豊富に用意されている ・独自のデータを用いたファインチューニング (追加学習) も、複雑な設定なしで実行可能 |
| 活用例 | ・最先端の画像認識や自然言語処理モデルを、自社アプリに最小限の開発コストで統合 ・特定の業界用語や社内ルールに最適化された、独自の対話型AIモデルの構築 |
これらのツールを活用することで、高度なスキルを持つ専門家がいなくても、機械学習のビジネス導入をスピーディーに開始できます。最初は「Canvas」や「JumpStart」でクイックに価値を検証 (PoC) し、必要に応じて詳細なカスタマイズへ移行するという柔軟なアプローチが可能です。
データ準備・管理 | Data Wrangler・Feature Store・Ground Truth
データ準備・管理は、機械学習において最も工数がかかると言われる「データの準備と管理」を効率化します。生データをモデルが学習できる形式に整え、再利用可能な形で管理することで、開発スピードと精度の向上が可能です。
AWSにおける主なデータ準備・管理は以下があります。
▼Data Wrangler
| 特徴 | ・機械学習のためのデータ集計・クリーニング・可視化をノーコードで実現する機能 ・複数の組み込みデータ変換機能 (欠損値の補完や型の変換など) をマウス操作だけで適用可能 ・S3・Redshift・Snowflakeなど、多様なデータソースに直接接続し、加工後のデータをシームレスに学習パイプラインへ出力 |
| 活用例 | ・複数のデータソースから収集した顧客データを統合し、機械学習に最適な形式に素早く加工 ・データの分布をグラフ化して可視化し、学習に悪影響を与える異常値やバイアスを事前に特定 |
▼Feature Store
| 特徴 | ・機械学習モデルの入力として使われる特徴量 (加工済みのデータ) を保存・共有・再利用するための専用リポジトリ ・リアルタイム推論用のオンラインストアと、バッチ学習用のオフラインストアの両方で一貫したデータを管理可能 ・特徴量のバージョン管理により、どのモデルがどのデータを使用したかを正確に追跡できる |
| 活用例 | ・複数のチームやモデル間で、共通の計算ロジック (例 : 直近30日の平均購入額) を再利用し、重複開発を防止 ・トレーニング時と推論時で同じ特徴量を使用することを保証し、モデルの予測精度の乖離を防止 |
▼Ground Truth
| 特徴 | ・機械学習モデルの学習に不可欠な教師データ (正解ラベル) を、高精度かつ効率的に作成するためのサービス ・自社スタッフ、専門業者、またはMechanical Turkのクラウドワーカーに、ブラウザベースの専用画面でラベル付けを依頼可能 ・自動データラベリング機能により、AIが一部のラベル付けを補助し、人間による作業工数を大幅に削減 |
| 活用例 | ・自動運転モデルの開発に向けた、数万枚規模の画像に対する歩行者や標識のバウンディングボックス (枠囲み) 付与 ・自然言語処理のための、大量のテキストに対する感情ラベルやカテゴリの割り当て |
これらのサービスを活用することで、機械学習にかかる時間の多くを占めると言われるデータ準備の時間を大幅に短縮できます。適切に管理・ラベル付けされたデータは、高精度なモデルを生み出すための大切な資産となります。
モデル監視・最適化 | Model Monitor・Debugger・Clarify
機械学習モデルは、時間の経過やデータの変化によって精度が低下することがあります。モデル監視・最適化のサービスは、運用中のモデルの状態を可視化し、常に最適なパフォーマンスを発揮できるよう維持・管理 (MLOps) します。
AWSにおける機械学習モデルの主なサービスは以下があります。
▼Model Monitor
| 特徴 | ・本番環境にデプロイされたモデルの予測精度を継続的に監視し、異常を自動で検知する機能 ・「データドリフト (入力データの傾向変化) 」や「コンセプトドリフト (予測対象の性質の変化) 」を特定し、再学習が必要なタイミングを通知 ・監視ルールを細かく設定でき、CloudWatchと連携した自動アラートも可能 |
| 活用例 | ・消費者の購買行動の変化により、需要予測モデルの精度が低下した際の早期発見 ・センサーデータの傾向が変わったことを検知し、故障予知モデルの誤検知を未然に防止 |
▼Debugger
| 特徴 | ・モデルの学習プロセスをリアルタイムで監視し、学習の停滞やエラー (勾配消失など) を検知する機能 ・学習中の内部状態を可視化し、システムリソース (CPU・メモリなど) の利用効率の最適化を支援 ・あらかじめ定義されたルールに基づき、学習中の問題を自動的にデバッグしてレポートを作成 |
| 活用例 | ・ディープラーニングなどの大規模な学習において、リソースの無駄遣いを防ぎつつ学習時間を短縮 ・モデルがうまく学習できていない原因 (過学習など) を特定し、精度向上に向けた改善を迅速化 |
▼Clarify
| 特徴 | ・機械学習モデルの予測結果に対する根拠を可視化し、説明可能なAI (XAI) を実現する機能 ・トレーニングデータやモデル自体に含まれる潜在的なバイアス (偏見や不公平) を検出し、レポート化 ・どの特徴量が予測に最も影響を与えたかを分析し、ブラックボックス化しやすいモデルの透明性を向上 |
| 活用例 | ・金融機関のローン審査モデルにおいて、なぜその判断に至ったかの根拠を説明・確認 ・採用や人事評価のアルゴリズムにおいて、性別や年齢による不当なバイアスが含まれていないかをチェック |
これらのサービスを導入することで、AIの精度の劣化や判断の不透明さというリスクを管理できます。安定した品質の維持と社会的な信頼性の担保は、機械学習をビジネスの基盤として定着させるために必要な要素です。
生成AI基盤モデル | Bedrock
生成AI基盤モデルは、テキスト生成・画像生成・会話・要約など、多様なタスクをこなす学習済みの大規模モデルをすぐに利用できるサービスです。インフラ管理の必要はありません。
AWSにおける生成AI基盤モデルの主なサービスは以下があります。
▼Bedrock
| 特徴 | ・AmazonやAnthropic・Meta・Mistral AIなどが提供する、複数の基盤モデル (FM) を単一のAPIから選択・利用が可能 ・サーバーレスサービスであるため、インフラの構築や管理を一切行うことなく、迅速に生成AIアプリケーションの開発を開始できる ・ユーザーのデータは基盤モデルの再学習に使用されないため、エンタープライズレベルの高いセキュリティとプライバシーを確保 ・Knowledge Bases (RAG) やAgentsなどの機能により、社内データに基づいた回答や、複雑なタスクの自動実行を容易に構築可能 |
| 活用例 | ・社内規定や技術ドキュメントと連携させた、高精度な自社専用ナレッジチャットボットの構築 ・大量のメールや会議録の自動要約、およびクリエイティブなマーケティングコピーの自動生成 |
Bedrockを活用することで、これまで膨大なリソースと専門知識が必要だった生成AIのビジネス活用が、APIを呼び出す感覚で手軽に実現できます。自社の独自データと組み合わせることで、汎用的なAIでは成し得ない自社特化型のインテリジェンスを短期間で構築が可能です。
AWS MLサービスの中心「SageMaker」とは?

AWSが提供する機械学習サービス群の中でも、中核を担うのが「SageMaker」です。今まで専門家のみが行えた高度な機械学習を、ビジネスの現場へ広く普及させるためのプラットフォームとしての役割を果たします。
SageMakerとは
SageMakerは、機械学習モデルの構築・学習・デプロイという一連のプロセスを一つの環境で完結できるフルマネージドサービスです。
サービスが提供する主な役割は以下の通りです。
| インフラ管理からの解放 | ・サーバーのプロビジョニング・ソフトウェアのセットアップ・パッチ適用などの煩雑な運用をAWSが自動で行う ・開発者はインフラの構築に時間を割くことなく、ビジネス課題を解決するためのモデル開発に専念できる |
| 高度なカスタマイズと拡張性 | ・標準的なアルゴリズムだけでなく、独自のコードやスクリプトを用いた自由度の高いモデル構築が可能 ・大規模なデータセットに対しても、複数の計算リソースを組み合わせた分散学習により高速な処理を実現 |
| アプリケーションへのスムーズな統合 | ・学習が完了したモデルを、ワンクリックでセキュアかつ高可用なAPIエンドポイントとして配備できる ・標準的なREST APIとして公開されるため、既存のWebサービスやモバイルアプリとの連携を容易に実現 |
SageMakerを活用することで、インフラの制約に縛られず、独自データに基づいた高品質な機械学習モデルを迅速にビジネスへ展開することが可能です。
SageMakerの主要な機能とツール
SageMakerは、開発・学習・運用の各フェーズを最適化するために、3つのコンポーネントと周辺ツールで構成されています。
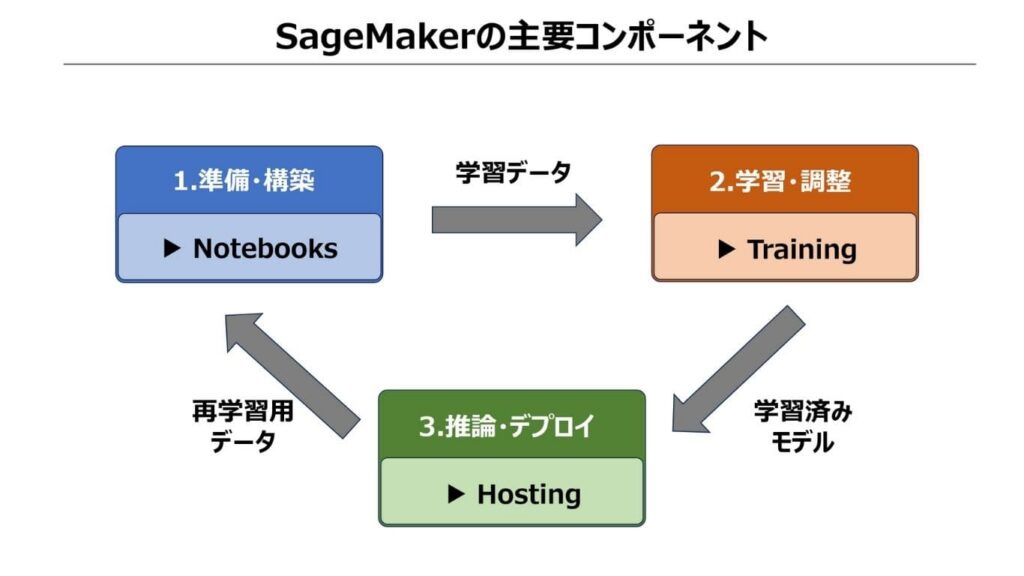
SageMakerの主なコンポーネントは以下の3つです。
▼主要コンポーネント
| ノートブック (Notebooks) | ・インタラクティブな開発環境 ・データの可視化やコードの記述をブラウザ上で行う |
| トレーニング (Training) | ・学習専用の環境 ・必要な時だけ高性能なリソースを起動し、効率的にモデルを学習 |
| ホスティング (Hosting) | ・予測実行環境 ・モデルを本番稼働させ、アプリケーションからの推論リクエストを処理 |
これらの3つのコンポーネントが緊密に連携することで、モデルの試作から本番環境でのサービス提供までを一貫してサポートします。
また、機械学習の運用 (MLOps) を支える周辺ツールは以下の通りです。
▼運用 (MLOps) を支える周辺ツール
| SageMaker Pipelines | データの加工からデプロイまでの工程をワークフローとして自動化し、継続的なモデル更新を実現 |
| SageMaker Experiments | 異なる条件で行った膨大な学習実験の履歴を記録・管理し、最適なモデルの特定を支援 |
| SageMaker Model Registry | 承認済みのモデルをバージョンごとに一元管理し、本番環境への安全なリリースを管理 |
これらのツール群を組み合わせて活用することで、機械学習モデルのライフサイクル全体を管理し、ビジネスの成長に合わせた継続的な品質改善が可能です。
SageMakerの利点と特徴
SageMakerを導入することで、最新の技術を迅速に取り入れつつ、コストを最適化しながら運用できるという大きなメリットがあります。
SageMakerの主な利点と特徴は以下の通りです。
| セットアップが容易で最新環境を即利用可能 | ・PyTorch・TensorFlow・Scikit-learnといった主要な機械学習フレームワークがプリインストールされている ・複雑なライブラリの依存関係を解消する手間がなく、最新の技術スタックですぐに開発を開始できる |
| 計算リソースを無駄なく利用できる経済性 | ・学習を実行する時のみ高性能なGPUインスタンスを立ち上げ、処理終了後は自動で停止する仕組みを採用 ・学習時のみの従量課金により、高価な計算リソースを自社で所有・維持するコストを大幅に削減可能 |
SageMakerは、最先端技術へのアクセスのしやすさと、高いコストパフォーマンスを両立させたプラットフォームです。導入することで、企業の投資対効果を大きく向上させます。
SageMakerとBedrockの使い分け
AWSの中心的な生成AIサービスには「SageMaker」と「Bedrock」があります。ビジネスの目的や開発のリソースに応じて、生成AIを適切に使い分けることが大切です。
「SageMaker」と「Bedrock」における、使い分けの基準は以下の通りです。
| SageMakerが適しているケース | ・独自のデータを深く学習させたオリジナルのモデルをゼロから開発・カスタマイズしたい場合 ・アルゴリズムの細かなパラメータ調整や、推論のパフォーマンス (応答速度など) を厳密に制御したい場合 |
| Bedrockが適しているケース | ・既存の強力な大規模言語モデル (LLM) をAPI経由ですぐに利用し、開発スピードを優先したい場合 ・モデル自体の管理よりも、プロンプトエンジニアリングや社内データとの連携 (RAG) など、活用側の構築に注力したい場合 |
独自モデルを一から構築し、アルゴリズムや推論性能を細かく制御したい場合は「SageMaker」が適しています。一方、既存の高性能な大規模言語モデルを活用し、開発スピードを重視する場合は「Bedrock」を選ぶのが一般的です。
SageMakerの料金体系

AWSで機械学習を導入する際は、コスト構造を正しく理解し、投資対効果 (ROI) を高めることが大切です。SageMakerは、小規模な実験から大規模な自動化まで、リソースの利用実態に即した柔軟な料金体系を採用しています。
SageMakerの料金モデル概要
SageMakerの基本は、使った分だけ支払う従量課金です。初期投資のリスクを最小限に抑えつつ、企業の進捗に合わせてコストをコントロールできる仕組みが整っています。
SageMakerの料金モデルの概要は以下の通りです。
| 初期費用なしの完全従量課金制 | ・サーバーのプロビジョニングや初期設定にかかる費用、および最低利用期間の制限 (解約料) は不要 ・インスタンスの稼働時間 (秒単位) やストレージ使用量に応じて料金が発生し、利用していない期間のコストをゼロに抑えることが可能 |
| 2ヶ月間の無料トライアルと無料利用枠 | ・利用開始から最初の2ヶ月間、特定の制限内であれば無料で試せる短期間トライアルが提供 |
| リージョンによる価格設定の差異 | ・料金単価は、サービスを実行するリージョンによって異なる |
SageMakerは、利用時間に応じたシンプルな課金モデルを軸に、無料トライアルや従量制を組み合わせることで、スモールスタートで始める環境を提供しています。
主要な課金対象
SageMakerのコストは、主に計算リソース (インスタンス) とデータ管理・付随機能の2つから発生します。2つの役割と課金の仕組みを理解することで、適切な予算管理を開始できます。
計算リソースとデータ管理・付随機能の主な課金対象は以下の通りです。
▼インスタンス利用料 (ノートブック・トレーニング・ホスティング)
| ノートブック | 開発者がコードを記述し、実験を行う環境の稼働時間に対して課金される |
| トレーニング | 機械学習モデルの学習を実行する際に使用するリソースの稼働時間に対して課金される |
| ホスティング | 作成したモデルを常時稼働させ、アプリケーションからの推論リクエストを受け付けるサーバーの稼働時間に対して課金される |
インスタンスのスペックによって料金は大きく異なり、CPUを中心とした汎用インスタンス(ml.m5など)から、高性能なGPUを搭載したインスタンス(ml.p4やml.g5など)まで、用途に応じた選択肢が用意されています。
画像認識や生成AIの学習には強力なGPUが必要となる一方、GPUの単価は汎用タイプの数倍から数十倍になるため、用途や精度目標に合わせたインスタンスタイプの選定がコストに直結します。
これらのインスタンス利用料は秒単位での従量課金となるため、使用していないリソースを確実に停止させることでコストを最小限に抑えることが可能です。
▼データ・付随機能の利用料
| データストレージ料金とデータ転送量 | ・ノートブックの作業領域や、学習データ・モデルを保存するS3およびFeature Storeのメタデータ保持量などに応じて課金される ・AWS外部へのデータ出力や、異なるリージョン間でのデータ移動の際に発生し、同一リージョン内でのS3とのデータ通信は基本的に無料または低コストとなる |
| 各種アドオン機能 (Canvasなど) | ・SageMaker Canvasは、プログラミング不要な環境の利用時間に加え、モデル作成時のデータ処理量に応じた課金が発生する ・Ground Truthは、データのラベリング (教師データ作成) を行った際、処理されたオブジェクトの数に応じた従量制となる |
データ量や高度なアドオン機能の利用状況によってもコストは変動します。計算リソースだけでなく、データの保存期間やツールの利用範囲をあわせて把握しておくことが重要です。
コスト最適化のポイント
SageMakerは、設定次第でコストが膨らむ可能性があります。AWSが提供するコストを最適化する仕組みを組み合わせることで、パフォーマンスを維持しながらコスト削減できます。
コスト削減の主な最適化のポイントは以下の通りです。
| SageMaker Savings Plans | ・1年または3年の期間、一定量の利用をコミットすることで、オンデマンド料金と比べて最大64%の割引が適用される ・ノートブックやトレーニング、推論など幅広いリソースが対象となる |
| マネージド型スポットトレーニング | ・AWSの余剰計算リソースを利用することで、モデルの学習費用を最大90%削減できる ・中断しても再開できる仕組みが備わっているため、緊急性の低い学習ジョブに極めて有効となる |
| 運用上の工夫とインスタンスの最適化 | ・作業していない間のノートブックインスタンスを検知し、自動でシャットダウンするライフサイクル設定やStudioのアイドル停止機能を活用する ・最初から高性能なGPUを選ばず、開発フェーズでは低コストなCPUインスタンスでコードを検証し、必要最小限のスペックを選択する |
これらの最適化手法を賢く活用することで、機械学習プロジェクトのフェーズや予算に合わせ、長期的に持続可能なコスト構造を構築することが可能です。
AWSの機械学習を効率良く学ぶためのポイント

AWSの機械学習サービスは多機能で範囲が広いため、効率的に活用するには体系的な学びと実践を組み合わせることが重要です。初心者から専門家まで、レベルに合わせて無理なくステップアップできる学習リソースが豊富に用意されています。
まずは公式チュートリアルで操作感を掴き、書籍で理論と構造を補完し、必要に応じて資格取得を目標に据えることで、実務に通用するレベルへ段階的に到達できます。
AWS公式チュートリアルと教材 (ラーニングプラン) の活用
AWSが提供する公式コンテンツは、最新かつ信頼性が高いため、学習をはじめるのに向いています。種類も豊富なため、自分の役割や目標に合わせた教材を容易に見つけることができます。
AWSが提供する主な公式コンテンツと特徴は以下の通りです。
| AWS Skill Builderによる無料学習 | ・「AWS Skill Builder」では、何百ものデジタル学習コースや、役割別に体系化された「ラーニングプラン」が無料で提供されている ・機械学習に特化したパスを選択することで、基礎から応用まで迷うことなく学習を進めることが可能 |
| ハンズオン教材 (10分間チュートリアルなど) | ・実際にAWSコンソールを操作しながら短時間で学べる「10分間チュートリアル」などのハンズオン教材が充実している ・理論だけでなく、実際に手を動かしてサービスを構築することで、具体的な設定の流れや操作感を効率よく習得できる |
公式のラーニングプランやハンズオン教材を軸に学習を進めることで、最新の仕様に基づいた知識と、実務でそのまま使える操作スキルを効率よく習得できます。
AWS関連書籍を用いた体系的な学習
AWSを学ぶための書籍は数多く出版されており、情報の網羅性と深い解説が強みとなります。公式教材と併せて書籍を活用することで、AWSの知識をより深く、体系的に定着させることができます。
書籍を選ぶポイントは以下の通りです。
| ・概説書と専門書を使い分ける ・サービス全体を網羅した概説書は、AWSの広大なサービス群の中で、機械学習の位置づけなどを俯瞰するために活用する ・特定のサービスに特化した専門書は、コード実装や、業務要件に基づいた詳細なアーキテクチャ設計を学ぶために選択する |
また、書籍で理論と実装を合わせて学ぶことで次のメリットがあります。
| ・機械学習の背景にある数学的な理論と、それをAWS上でどう実現するかという実装方法を学ぶことで、技術の本質的な理解が進む。 ・ツールの使い方に留まらず、なぜそのアルゴリズムを選ぶのかという根拠を明確に持てるようになる。 |
公式チュートリアルで操作を学び、書籍でその背景にある理論と構造を補完することで、実務で応用が利くスキルセットを習得できます。
AWSの資格取得
AWSの認定資格を取得することは、AWSの知識を測る尺度となります。また、認定資格の取得を目指すことは、モチベーションの維持だけでなく、実務に裏打ちされた体系的な知識を効率よく習得できます。
AWSの認定資格を取得する主なメリットは以下の通りです。
| 知識の証明と体系的な理解 | ・「AWS Certified Machine Learning Engineer – Associate」などの認定資格を取得すると、客観的に専門性スキルを証明できる ・試験対策を通じて、網羅的な知識を効率よく習得できる |
| 実務に直結する設計・選定スキル | ・各サービスの制限や最適な組み合わせを学ぶことで、実務での構成検討力が向上する ・セキュリティやコスト最適化など、AWSのベストプラクティスを検討する知識が身につく |
資格取得に向けた体系的な学習は、個人のスキルアップのみならず、組織全体として「正しく、効率的なAWS活用」を推進するための土台となります。
まとめ
AWSの機械学習サービスは、手軽に導入できるAIサービスから本格的な開発が可能なSageMakerまで多岐にわたります。各サービスの役割や料金体系、効率的な学習方法を正しく把握することで、ビジネスの課題に合わせた最適なAIを低コストかつ低リスクで活用できます。
まずは無料利用枠や公式チュートリアルを活用し、自社の身近な課題を解決するスモールスタートで検証しながら始めてみましょう。
AWSの生成AI導入なら、国内25,000人以上 (*1) の技術者を擁し、大手企業を中心に2,555社との取引実績 (*2) を持つ株式会社テクノプロにお任せください。最適な運用設計から監視・障害対応・コスト最適化まで、一括して任せることができます。
*1: 2024年6月末時点
*2: (株)テクノプロ及び(株)テクノプロ・コンストラクション 2024年6月末時点
監修者

テクノプロ・ホールディングス株式会社
チーフマネージャー
中島 健治
2001年入社
ITエンジニアとして25年のキャリアを持ち、チーフマネージャーとしてテクノプロ・エンジニアリング社にて金融・商社・製造業など多業界でのインフラ基盤構築に従事してきた。2008年から2024年まで、オンプレミス環境でのストレージ・サーバ統合基盤の設計・構築を手掛け、特に生成AI・データ利活用分野のソリューション開発実績が評価されている。現在は技術知見を活かしたマーケティング戦略を推進している。






